2023 is going to be a tough year for anybody managing technology. As we face the repercussions of inflation and high interest rates and the bubble of tech starts to be burst, we are seeing a combination of hiring freezes, increased focus on core business activities and the hoary request to “do more with less.”
Behind the cliche of doing more with less is the need to actually become more efficient with tech usage. This means adopting a FinOps (Financial Operations) strategy to cloud to go with your existing Telecom FinOps (aka Telecom expense) and SaaS FinOps (aka SaaS Management) strategies. And it means being prepared for new spend category challenges as companies will need to invest in technology to get work done at a time when it is harder to hire the right person at the right time. Here is a quick preview of our predictions.
14 Key Predictions for the IT Executive in 2023
To get the details on each of these trends and predictions and understand why they matter in 2023, download this report at no cost by filling out this quick form to join our low-volume bi-monthly mailing list. (Note: If you do not wish to join our mailing list, you can alsopurchase a personal license for this report.)
“Innovation distinguishes between a leader and a follower.”
Steve Jobs
In 2023, we face a series of global planning challenges across accounting, finance, supply chain, workforce management, information technology, and data management. Each of these challenges involves a different set of stakeholders, data structures, key performance indicators, and broader economic and environmental drivers.
In light of this increasingly complex and nuanced set of categories that now make up the responsibilities associated with financial performance management (also known as enterprise performance management; corporate performance management; budgeting, planning, and forecasting, and other buzzwords, but all basically coming back to the financial planning and analysis FP&A role that we have known for decades), companies face a technology-related challenge for managing business plans. Is it better to work with a platform-based approach that allows every user to use the same application to support a variety of accounting and finance use cases including consolidation, close, and planning? Or is it better to use a Best-in-Breed application for business planning?
The basic starting point for evaluating this decision starts with a common sense question for enterprises: is it worth spending money on a standalone planning application or is it better to bundle planning with consolidation and transactional accounting such as an ERP or an accounting platform? In making this decision, companies should look at the following considerations:
Is the solution easy to use? In the 2020s, planning apps should be fairly easy to use, including ease of data entry, the ability to analyze data once it is entered, collaborative planning with other colleagues or budget-holding executives, mobile app support, and the ability to drill into planning data to explore specific deltas, outliers, and budget categories that are of specific interest. Ease of use should also extend to model and scenario management as financial professionals seek to bring a wide variety of potential considerations to enterprise forecasting environments. This ease of use is especially important as planning and forecasting exercises have accelerated in the 2020s based on COVID, supply chain challenges, currency value shifts, inflation, and the looming threat of a potential recession. The need to support flexible planning scenarios can be challenging to accomplish within the accounting framework of creating a fixed and defined set of data that is fully consolidated and auditable.
Is the current solution integrated with all of the data – including operational data – that is needed from a planning perspective? If spreadsheets are considered, this immediately leads to potential governance and consistency problems as each individual will probably have their own specific assumptions. Suppose companies are using a planning solution as part of their ERP. In that case, the planning solution will likely have access to the majority of accounting data associated with planning. Still, companies then have to see how much of their semi-structured data, third-party data (such as weather, government, or market-based data), and other external data are integrated into a solution. And do these integrations require significant IT support or can they be supported either by the vendor, line-of-business operations manager, or even by the end users, themselves?
Is the current planning solution flexible enough to both provide each department with the level of planning they are trying to perform while providing a consistent and shared version of the truth? Over the past few decades, the worlds of enterprise analytics and business accounting have both focused on the idea of a rigid “single version of the truth,” but the reality is that there is no single version of the truth as each individual and each department typically has specific goals, assumptions, terminology, and performance drivers specific to their specific job roles. And the moment that data is officially published or defined as “clean,” it immediately starts becoming outdated.
Accordingly, planning data needs to be organized so that every person involved in planning is able to access a consistent set of metrics while also having specialized views of the operational benchmarks and drivers associated with their specific goals as well as the ability to explore specific “what-if” hypothetical scenarios related to the variability of business situations that the organization may encounter. The operational data needed to support this level of flexibility is not always included as part of a core ERP suite and may need to come from a variety of transactional, payment, process automation systems, workflow management, and project management solutions to provide the level of clarity needed to support enterprise planning.
From Amalgam Insights’ perspective, this initial question of planning application vs platform is a bit of a red herring. Consolidation, close, and accounting audits are based on the need to lock down every transaction and document what has happened in the past. This historical view provides guidance and can be reviewed as necessary. But planning and forecasting are exercises in constructing the present and future of a business that requires the need to view the company through multiple lenses and scenarios and need to be altered based on possible business or global activities that may never happen. By nature, financial planning and analysis activities involve some level of uncertainty. Organizations seeking to accelerate the pace of planning and to extend planning beyond pure financial planning into sales, workforce, supply chain, information technology, & project portfolio management, will likely find that the need for near real-time analytics and data management increasingly requires an application that combines analytic speed, collaboration, and the ability to experiment within an application in ways that may conflict with or surpass the rate of accounting. Business planning needs to be a Best-in-Breed capability that allows for the flexibility of what-if analysis, the real-time feedback associated with new data and business considerations, the scale of modern data challenges, and the ability to collaboratively work with relevant business stakeholders. Without these supporting capabilities that can help organizations to independently adjust to the future, financial planning is ultimately a compliance exercise that lacks the impact and strategic guidance that executive teams need to make hard decisions.
“The will to win means nothing without the will to prepare”
Boston Marathon champion Juma Ikangaa
2023 is undoubtedly a challenging year to forecast from an economic perspective as the tempest of inflation, stock market volatility, foreign exchange challenges, hiring freezes, supply chain delays, and geopolitical conflicts are creating pressure for companies of all sizes and industries. As companies seek to make sense of a complex world and forecast performance, it is important to take full advantage of planning and forecasting capabilities to provide guidance. Of course, it is important to provide visibility and report to business stakeholders. But beyond the basics, what should you be thinking about as we prepare for a bumpy ride? Here are five key recommendations Amalgam Insights is providing for the business community.
Build a planning process that can be changed on a monthly basis. Even if your organization does not need to plan on a continuous basis, there will be at least one or two unexpected planning events that happen this year that will require widespread reconsiderations of the “annual plan.” The “annual planning cycle” concept is dead at companies after the past three years of working through COVID, supply chain issues, and workforce shortages. This means that planning often has to be updated with new and unexpected data to support a wide variety of scenarios. Locking the plan to a specific structure, schedule, or level of data consolidation is increasingly challenging for companies seeking better guidance throughout the year. If you are not building out a variety of scenarios and tweaking changes throughout the year based on business issues and changes, your business is working at a disadvantage to more nimble and agile organizations.
2. Identify planning anomalies quickly. As businesses review their plans, they will find that they are off-plan more quickly than they have historically been. One example of this is in cloud computing, a spend area that is expected to grow 18-22% in 2023, far above general IT spend or the expected rate of inflation in 2023. Other commodities such as complex manufactured goods and food stocks may fall into this category as well based on production delays, logistical shortages, & new novel diseases interrupt supply chains. The ability to quickly identify spend anomalies that exceed budgetary expectations allows companies to affect spend, procurement, and technologies strategies that may further optimize these environments. By identifying these anomalies quickly, finance can work with procurement both to figure out opportunities to reduce spend and to find alternative providers that can either reduce cost or ensure business continuity to meet consumer demand.
3. Interest rates and the cost of money may incentivize longer sourcing contracts to lock in costs. This lesson comes from the sports world, where baseball players are getting long contracts this year. Why? Because the cost of money is increasing and baseball teams can’t play games without players, leading teams to seek the opportunity to lock in costs. Of course, to do this, companies must budget for the potential upfront costs associated with taking on new contracts. This is a story of Haves and Have-nots where the haves now possess an opportunity to lock in costs for the next few years and take advantage of the value of money over the next couple of years while the Have Nots struggling to visualize their spend may be locked in short-term contracts that will cost more over time. However, this ability to make decisions based on the current cost of money is dependent on the ability to forecast the potential ramifications of locking in cost, especially when those costs represent the variable cost of goods to meet the demand for consumer purchases and services.
4. Cross-departmental business planning requires a data strategy that allows organizations to bring in multiple data sources. Finance must start learning about the value of a data pipeline and potentially a data lake for bringing data into a planning environment, processing and formatting the data properly, and maintaining a consistent store of data that includes all relevant information for modern business planning use cases. In the past, it may have been enough for finance to know that there was a database to support financial and payment information and then an OLAP cube to provide high-performance analytics for business planning. But in today’s planning world where finance is increasingly asked to be a strategic hub based on its view of the entire business, planning data now potentially includes everything from weather trends to government-provided data to online sentiment and even social media. These new data sources and formats require finance to both store and interact with data in ways that exceed the challenges of simply having massive row-based tables of business data.
5. Look for arbitrage opportunities across currencies, geographies, and even internal departments. The valuation of mission-critical skills and resources can be valued very differently across different areas. 2023 is an environment where corporate equity and stock values are lower, the US dollar is strong against the majority of global currencies, and skills and commodities can be hard to find. These are both challenges and opportunities, as they allow FP&A professionals to dig into forecasted costs and see if there are opportunities to go abroad or to look internally for skills, goods, and resources that may be less expensive than the typical markets businesses participate in. Finance can work with sourcing, human resources, information technology, and other departments to proactively identify specific areas where the business may have an opportunity to improve.
As we plan for 2023, it is time to prepare sagaciously so that we are ready to execute when challenges and opportunities emerge. By planning now for a wide variety of potential situations, businesses can make better decisions in critical moments that can define careers and the future of the entire organization.
“If you think it’s expensive to hire a professional to do the job, wait until you hire an amateur.”
Red Adair
In 2023, workforce planning is significantly more challenging and requires a combination of headcount, skills, finance, sourcing, and automation management. We are facing a remarkable confluence of labor trends that force workforce management to be more closely tied to financial management. Workforce volatility is at a peak as the Great Resignation has led to a mass exodus that has been augmented in recent months by layoffs from companies that overstaffed in the now-halcyon days of the favorable market that has defined our economic environment over the past decade. At the same time, the demand for specialized talent continues as the need to market, sell, deliver, produce, and digitize is still there for companies that are still healthy. And all this is happening at a time of global inflation and currency exchange challenges leading to cost constraints and explorations of geographic arbitrage and automation to introduce and scale up skills. This financial uncertainty leads to the increasing need for finance to support the details of workforce planning to build better businesses.
But this combination of volatility and demand has led to a more uneven distribution of talent that must be reconciled. From a practical perspective, this means that it is more important to make a business case for each hire that accurately estimates the value of a new employee’s skills and capabilities with the expected revenue per employee ratio that the company seeks to achieve. New employees must bring a combination of organizational fit and rapidly deployable skills to their companies to create value in a timely fashion. Considering that the cost of finding, onboarding, and ramping up a new employee can range from $15,000 to $50,000 based on Amalgam Insights’ estimates, companies face the challenge of ensuring that new employees are put in a position to succeed. From a planning perspective, this means having hardware, software licenses, data access, training, and relevant employee relationships all defined on Day Zero or Day One rather than a penny-wise, pound-foolish approach of attempting to provide just-in-time access as employees demand it.
Workforce planning may also include investing in training or learning and development resources proactively as skills needs are forecasted, as the cost of training can be lower than the cost of hiring a new employee or finding a new consultant. From a financial perspective, it is important to conduct a cost analysis of skills acquisition based on the future-facing needs of the organization. Even in a cost-conscious environment, it takes money to make money. However, workforce investments must be focused on employees who will both create value quickly and have the mindset to provide long-term value through their problem-solving, self-improvement, and collaborative approaches. And in considering the cost of skills, companies need to consider both the need for hard skills such as process automation and machine learning as well as the need to teach and train soft skills such as effective project coordination and corporate communications skills. By accounting for skills that may only be needed on a short-term basis compared to those that represent long-term commitments for an organization, companies can prioritize workforce planning from a more quantitative and business growth-oriented perspective.
As companies consider the full cost of employee skills, companies also have to consider the fully loaded cost of an employee, including the resources and benefits associated with bringing an employee on board. The accounting for supporting employee productivity has become more complex in the face of COVID and the subsequent reimagining of the overhead associated with employees. At the peak of COVID, an estimated 40% of employees worked from home. Based on this trend, it was not difficult for organizations to start scrutinizing the real estate and other long-term assets and leases that have traditionally been seen as depreciable aspects of employee cost providing tax benefits over time. The increasing willingness to move headquarters and other large offices to more tax or cost-of-living-friendly locations as well as the tradeoffs between depreciation, asset sales, and leases are increasingly relevant to structuring workforce planning. Companies must readjust the cost assumptions of their workforce to reflect the new reality of their organization.
This set of assumptions does not simply mean that companies can assume that an employee will be fully remote or fully on-site, as this discussion is driven by a nuanced set of considerations. Remote workers have struggled to onboard and reach full productivity and younger workers have sought mentorship and leadership that has traditionally been provided on-site. On the other hand, experienced specialists point to greater productivity and efficiency when they work in remote environments where they run into fewer ad-hoc distractions and interruptions and can work more flexibly. [1]
From a planning perspective, this may mean setting up scheduled hybrid assumptions for workforce overhead that include office space and physical resources on a monthly or quarterly basis depending on the roles involved. Real estate and other long-term assets/leases that have traditionally been seen as depreciable aspects of employee cost providing tax benefits over time, but with large office vacancies and the increasing willingness to move headquarters and other large offices, the tradeoffs between depreciation, asset sales, and leases are now increasingly relevant to structuring workforce planning. Amalgam Insights expects that 2023 will be a year where companies are still struggling to find the correct balance of office space and may find themselves overcompensating in ways that affect long-term productivity.
The cost of bringing a workforce to full productivity at scale is seen through a variety of data, including the United States economic census, which shows that small companies under 500 employees make approximately $220,000 per employee while large enterprises with over 5,000 employees make over $375,000 per employee. (SOURCE: United States 2017 County Business Patterns and Economic Census) This difference of over $150,000 speaks to the potential difference in productivity between employees who are fully supported at an enterprise level and their small business counterparts who presumably have less support, brand power, and capabilities to enhance their efforts.
But this increase is ultimately only possible by aligning workforce planning efforts with the financial planning and forecasting efforts that align talent and skills with business strategy and outcomes. Ultimately, workforce planning and business planning must be intertwined to be successful across business demand, skills, onboarding, and overhead.
2022 was a banner year for artificial intelligence technologies that reached the mainstream. After years of being frustrated with the likes of Alexa, Cortana, and Siri and the inability to understand the value of machine learning other than as a vague backend technology for the likes of Facebook and Google, 2022 brought us AI-based tools that was understandable at a consumer level. From our perspective, the most meaningful of these were two products created by OpenAI: DALL-E and ChatGPT, which expanded the concept of consumer AI from a simple search or networking capability to a more comprehensive and creative approach for translating sentiments and thoughts into outputs.
DALL-E (and its successor DALL-E 2) is a system that can create visual images based on text descriptions. The models behind DALL-E look at relationships between existing images and the text metadata that has been used to describe those images. Based on these titles and descriptions, DALL-E uses diffusion models to start with random pixels that lead to generated images based on these descriptions. This area of research is by no means unique to OpenAI, but it is novel to open up a creative tool such as DALL-E to the public. Although the outputs are often both interesting and surprisingly different from what one might have imagined, they are not without their issues. For instance, the discussion around the legal ownership of DALL-E created graphics is not clear, since Open AI claims to own the images used, but the images themselves are often based on other copyrighted images. One can imagine that, over time, an artistic sampling model may start to appear similar to the music industry where licensing contracts are used to manage the usage of copyrighted material. But this will require greater visibility regarding the lineage of AI-based content creation and the data used to support graphic diffusion. Until this significant legal question is solved, Amalgam Insights believes that the commercial usage of DALL-E will be challenging to manage. This is somewhat reminiscent of the challenges that Napster faced at the end of the 20th century as a technology that both transformed the music industry and had to deal with the challenges of a new digital frontier.
But the technology that has taken over the zeitgeist of technology users is ChatGPT and related use cases associated with the GPT (Generative Pre-Trained Transformer) autoregressive language model trained on 500 billion words across the web, Wikipedia, and books. And it has become the favorite plaything of many a technologist. What makes ChatGPT attractive is its ability to take requests from users asking questions with some level of subject matter specificity or formatting and to create responses in real-time. Here are a couple of examples from both a subject matter and creative perspective.
Example 1: Please provide a blueprint for bootstrapping a software startup.
This is a bit generic and lacks some important details on how to find funding or sell the product, but it is in line with what one might expect to see in a standard web article regarding how to build a software product. The ending of this answer shows how the autogenerative text is likely referring to prior web-based content built for search engine optimization and seeking to provide a polite conclusion based on junior high school lessons in writing the standard five-paragraph essay rather than a meaningful conclusion that provides insight. In short, it is basically a status quo average article with helpful information that should not be overlooked, but is not either comprehensive or particularly insightful for anyone who has ever actually started a business.
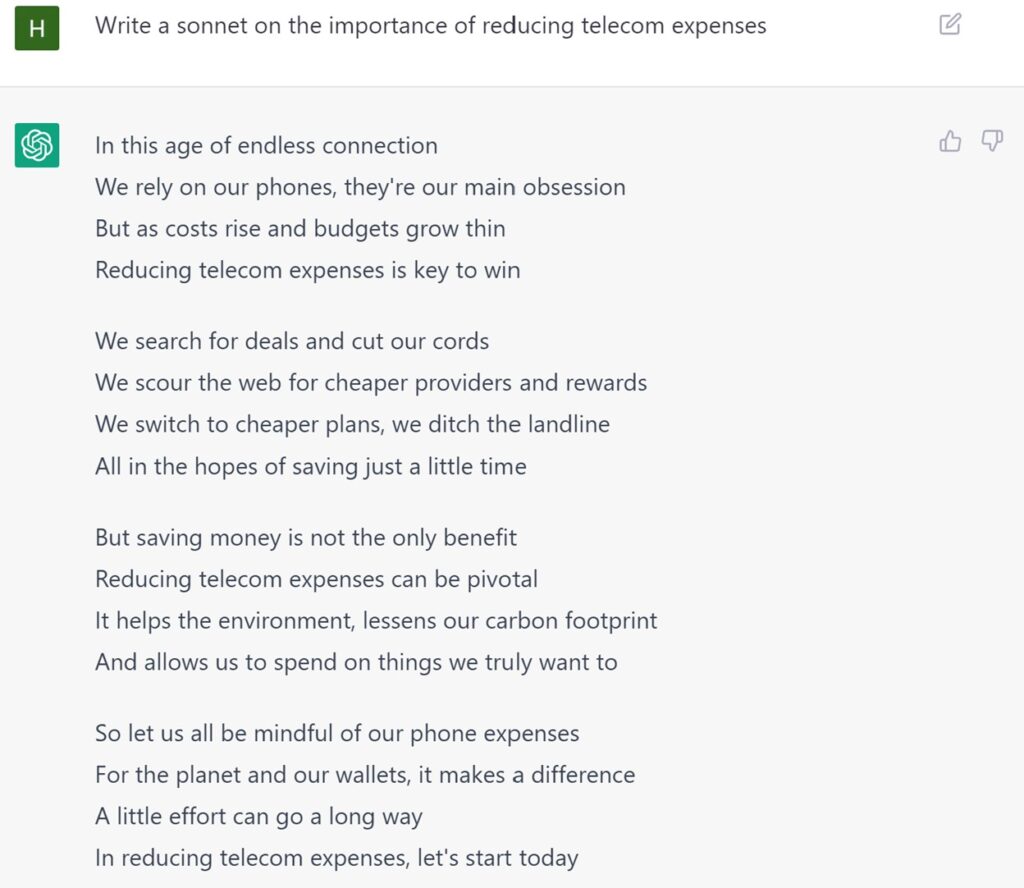
A second example of ChatGPT is in providing creative structural formats for relatively obscure topics. As you know, I’m an expert in technology expense management with over two decades of experience and one of the big issues I see is, of course, the lack of poetry associated with this amazing topic. So, again, let’s go to ChatGPT.
Example 2: Write a sonnet on the importance of reducing telecom expenses
As a poem, this is pretty good for something written in two seconds. But it’s not a sonnet, as sonnets are 14 lines, written in iambic pentameter (10 syllable lines split int 5 iambs, or a unstressed syllable followed by a stressed syllable) and split into three sections of four lines followed by a two-line section with a rhyme scheme of ABAB, CDCD, EFEF, GG. So, there’s a lot missing there.
So, based on these examples, how should ChatGPT be used? First, let’s look at what this content reflects. The content here represents the average web and text content that is associated with the topic. With 500 billion words in the GPT-3 corpus, there is a lot of context to show what should come next for a wide variety of topics. Initial concerns of GPT-3 have started with the challenges of answering questions for extremely specific topics that are outside of its training data. But let’s consider a topic I worked on in some detail back in my college days while using appropriate academic language in asking a version of Gayatri Spivak’s famous (in academic circles) question “Can the subaltern speak?”
Example 3: Is the subaltern allowed to fully articulate a semiotic voice?
Considering that the language and topic here is fairly specialized, the introductory assumptions are descriptive but not incisive. The answer struggles with the “semiotic voice” aspect of the question in discussing the ability and agency to use symbols from a cultural and societal perspective. Again, the text provides a feeling of context that is necessary, but not sufficient, to answer the question. The focus here is on providing a short summary that provides an introduction to the issue before taking the easy way out telling us what is “important to recognize” without really taking a stand. And, again, the conclusion sounds like something out of an antiseptic human resources manual in asking for the reader to consider “different experiences and abilities” rather than the actual question regarding the ability to use symbols, signs, and assumptions. This is probably enough of an analysis at a superficial level as the goal here isn’t to deeply explore postmodern semiotic theory but to test ChatGPT’s response in a specialized topic.
Based on these three examples, one should be careful in counting on ChatGPT to provide a comprehensive or definitive answer to a question. Realistically, we can expect ChatGPT will provide representative content for a topic based on what is on the web. The completeness and accuracy of a ChatGPT topic is going to be dependent on how often the topic has been covered online. The more complete an answer is, the more likely it is that this topic has already been covered in detail.
ChatGPT will provide a starting point for a topic and typically provide information that should be included to introduce the topic. Interestingly, this means that ChatGPT is significantly influenced by the preferences that have built online web text over the past decade of content explosion. The quality of ChatGPT outputs seems to be most impressive to those who treat writing as a factual exercise or content creation channel while those who look at writing as a channel to explore ideas may find it lacking for now based on its generalized model.
From a topical perspective, ChatGPT will probably have some basic context for whatever text is used in a query. It would be interesting to see the GPT-3 model augmented with specific subject matter texts that could prioritize up-to-date research, coding, policy, financial analysis, or other timely new content either as a product or training capability.
In addition, don’t expect ChatGPT to provide strong recommendations or guidance. The auto-completion that ChatGPT does is designed to show how everyone else has followed up on this topic. And, in general, people do not tend to take strong stances on web-based content or introductory articles.
Fundamentally, ChatGPT will do two things. First, it will make mediocre content ubiquitous. There is no need to hire people to write an “average” post for your website anymore as ChatGPT and other technologies either designed to compete with or augment it will be able to do this easily. If your skillset is to write grammatically sound articles with little to no subject matter experience or practical guidance, that skill is now obsolete as status quo and often-repeated content can now be created on command. This also means that there is a huge opportunity to combine ChatGPT with common queries and use cases to create new content on demand. However, in doing so, users will have to be very careful not to plagiarize content unknowingly. This is an area where, just like with DALL-E, OpenAI will have to work on figuring out data lineage, trademark and copyright infringement, and appropriation of credit to support commercial use cases. ChatGPT struggles with what are called “hallucinations” where ChatGPT makes up facts or sources because those words are physically close to the topic discussed in the various websites and books that ChatGPT uses. ChatGPT is a text generation tool that picks words based on how frequently they show up with other words. Sometimes that result will be extremely detailed and current and other times, it will look very generic and mix up related topics that are often discussed together.
Second, this tool now provides a much stronger starting point for writers seeking to say something new or different. If your point of view is something that ChatGPT can provide in two seconds, it is neither interesting or new. To stand out, you need to provide greater insight, better perspective, or stronger directional guidance. This is an opportunity to improve your skills or to determine where your professional skills lie. ChatGPT still struggles with timely analysis, directional guidance, practical recommendations beyond surface-level perspectives, and combining mathematical and textual analysis (i.e. doing word problems or math-related case studies or code review) so there is still an immense amount of opportunity for people to write better.
Ultimately, ChatGPT is a reflection of the history of written text creation, both analog and digital. Like all AI, ChatGPT provides a view of how questions were answered in the past and provides an aggregate composite based on auto-completion. For topics with a basic consensus, such as how to build a product, this tool will be an incredible time saver. For topics that may have multiple conflicting opinions, ChatGPT will try to play either both sides or all sides in a neutral manner. And for niche topics, ChatGPT will try to fake an answer at what is approximately a high school student’s understanding of the topic. Amalgam Insights recommends that all knowledge workers experiment with ChatGPT in their realm of expertise as this tool and the market of products that will be built based on the autogenerated text will play an important role in supporting the next generation of tech.
The biggest US-based travel story at the end of 2022 was the absolute collapse of Southwest Airlines. The United States was hit by a sudden cold snap just as Christmas approached, leading to a massive travel delay across almost all travel modes including airlines, trains, and road-based transit. However, after a couple of days, most US-domestic airlines seemed to have recovered with the exception of Southwest, which suddenly and unexpectedly canceled nearly all of its flights in the last week of 2022, just as people were traveling from or to locations for Christmas, Hanukkah, New Year’s Eve, and other holidays. The timing was horrible and inexplicable. And with little to no official explanation, travelers stranded across the country could only guess whether this was due to an unannounced strike. Were there problems with Southwest’s airplane fleet? Were there problems with a specific airport?
It turns out that the problem was with Southwest’s internal scheduling tool, an in-house software application built in the 1990s and held together over the years as Southwest roughly doubled in size across passengers, planes, trips, employees, and number of destinations supported. This complexity ended up being especially challenging because Southwest’s model as a regional airline meant that it did not use a central hub as most other large airlines in the United States use. Rather, each plane flies from point to point leading to a combination of possibilities that grew exponentially rather than linearly. Although Southwest does not fly every plane from each location to every other location, the complexity of operations from roughly 45 locations in the late 1990s to roughly 100 domestic locations today is not a doubling of complexity but more along the lines of N*(N-1)/2, as long-time analytic advisor Neil Raden pointed out. This means the complexity increase is more akin to (45*44/2) = 990 vs. (100*99/2) = 4950. This level of complexity is multiplied by the challenges of organizing the thousands of pilots and flight attendants traveling from point to point every day.
The orders of magnitude in complexity associated with this scheduling system had already been strained in previous years but met a critical breaking point at the end of 2022 due to a lack of investment and modernization. This failure is a textbook example of the concept of “technical debt.”
Technical debt is often described as a concept that is difficult to articulate for a business audience, but the concept is actually very straightforward from a business perspective. Just as with financial debt, which must be paid back with interest or risk a default that threatens business assets, technical debt is an act of borrowing against the future. Like financial debt, technical debt either requires future investment (the “interest”) to fix the technology over time or to accept that the technology will fail (“default”) and lead to breaking down any processes dependent on the technology.
The lessons from this breakdown are straightforward but are potentially challenging to follow in 2023, a year where companies will be tempted to cut costs by any means possible.
Ensure that executive stakeholders are clear both on the concept of technical debt and the labor associated with current technical debt. It may not be possible to put an exact dollar amount on the technical debt that currently exists in the organization, but it should be possible to provide some guidance on the current labor and resources assigned to managing outdated technology as well as the potential points of failure associated with, say, being unable to find a FORTRAN developer quickly or the use of applications no longer supported by a vendor or by in-house developers.
Document every technology associated with each mission-critical process. With the cliché that “every company is a technology company” having been fully realized in today’s web, mobile, and automated world, IT’s job is to provide proactive guidance on the hardware, software, and skills that must either be supported or upgraded. The business value propositions of IT asset and service management are unlocked when assets are specifically aligned to business dependencies, projects, and processes.
Identify technologies where business growth lead to exponential technology demand. Southwest’s scheduling system needed to grow exponentially and eventually failed based on its legacy design. Look at the mathematics associated with key processes to see if growth is logarithmic, linear, exponential, or unpredictable. Simply assuming that a process grows linearly with revenue, employee growth, or business traffic can be a job-ending mistake.
Ensure that legacy technologies have the capacity to support forecasted business complexity or business growth. Any time technology growth needs to expand faster than overall IT spend or overall operational spend, it should serve as a warning sign to either change the technological approach or to invest in the necessary capacity.
We face a challenging year as inflation, foreign currency challenges, geopolitical issues, and supply chain bottlenecks still threaten the spectre of recession. But as executives seek to cut costs, Southwest serves as a reminder that businesses must still futureproof their technology approaches, evaluate the scalability of their processes, and invest in service delivery commensurate with their brand promise or risk lasting revenue and market capitalization losses.
$200M F Round for Dataiku from Wellington Management This week, Wellington Management led the latest round of funding for AI stalwart Dataiku, a Series F round of $200M. DAtaiku will use the funding for continued growth and expansion of its platform capabilities.
Launches and Updates
Data Lineage Now Generally Available in Databricks Unity Catalog On December 12, Databricks announced the general availability of data lineage in their Unity Catalog governance solution, after six months of being in preview. Customers at the Databricks Premium and Enterprise tiers now have access to automatically captured data lineage at no extra cost; they will need to restart their clusters or SQL Warehouses that were last started prior to December 7.
insightsoftware Launches Jet Analytics Cloud On Monday, insightsoftware released Jet Analytics Cloud, a managed services offering of the Jet Analytics data prep and analytics tool. Jet Analytics Cloud is now available on the Azure public cloud.
MarkLogic Modernizes with Version 11 Veteran data platform MarkLogic announced MarkLogic 11 earlier this week. Key modernization features include improved support for GraphQL, OpenGIS and GeoSPARQL, and OAuth; extended capabilities for the MarkLogic Optic API; more flexible deployment and management options, including support for Docker and Kubernetes; and improved observability, auditability, and manageability capabilities.
MathWorks Debuts Modelscape for Model Management in Regulated Industries On December 15, MathWorks released Modelscape, a suite of products designed to help primarily financial institutions reduce risk during the model lifecycle while complying with regulatory requirements. The products include Modelscape Governance, which provides centralized access to models, dependencies, metadata, lineage, audit trail, risk scoring, and overall model risk reporting; Modelscape Develop, to develop models with automated documentation and reproducible processes; Modelscape Validate, to validate models; Modelscape Test, to automatically test models before putting them into production; Modelscape Deploy, to deploy models into production without recoding, with both on-prem and cloud options; and Modelscape Monitor, to monitor, analyze, and report on model performance in a dashboard scenario.
SingleStore Announces Version 8.0 SingleStore released version 8.0 of their cloud-native database this week. New capabilities include better query performance with semi-structured data such as JSON data, dynamic workspace scaling, new realtime and historical monitoring capabilities, and OAuth support.
Partnerships
Microsoft and London Stock Exchange Group Announce Long-Term Strategic Partnership Microsoft and the London Stock Exchange Group have announced a decade-long strategic partnership. LSEG’s data infrastructure will be architected on the Microsoft cloud, and both companies will co-develop new data and analytics products and services. In addition, Microsoft has agreed to purchase a 4% equity stake in LSEG by acquiring shares from the Blackstone/Thomson Reuters Consortium.
Panoply by SQream Now In the Google Cloud Marketplace Data analytics acceleration platform SQream is now available in the Google Cloud Marketplace. Panoply users will be able to purchase Panoply within GCM, then set up a Google BigQuery instance within Panoply and connect their data.
Syniti Match and Syniti Replicate Available on SAP® Store Enterprise data management company Syniti has made Syniti Match and Syniti Replicate available in the SAP Store. Syniti Match, integrated with SAP HANA, is data matching software, while Syniti Replicate provides data integration and realtime data streaming. Replicate can also integrate with both SAP HANA and SAP S/4HANA, with change data capture capability and data lake operations.
Semantic layer platform AtScale announced Thursday that it was now available on Google Cloud Marketplace. Mutual customers will be able to use AtScale on Google Cloud with services such as Google BigQuery, where they can run BI and OLAP workloads without needing to extract or move data.
Open data lakehouse Dremio announced a number of improvements this week. Among the updates: new SQL functionality, including support for the MAP data type so users can query map data from Parquet, Iceberg, and Delta Lake; security enhancements such as row and column-level policy-defined access control for users; support for INSERT, DELETE, and UPDATE on Iceberg tables, and for “time travel” to query historical data in place; as well as usability and performance improvements. Dremio also added a number of connectors, including dbt, Snowflake, MongoDB, DB2, OpenSearch, and Azure Data Explorer.
At AWS re:Invent 2022, Informatica announced three new capabilities for Informatica within AWS. Informatica Data Loader is embedded within Amazon Redshift so that mutual customers will be able to ingest data from a wide variety of systems, including AWS. The Informatica Data Marketplace now supports AWS Data Exchange, allowing customers to access and use third-party data hosted on the Data Exchange. And Informatica INFACore, INFA’s new development and data science framework, simplifies the process of developing and maintaining complex data pipelines, which can be shunted over to Amazon SageMaker Studio as a simple function, allowing users to pull prepared data from INFACore into SageMaker Studio for further use in building, training, and deploying machine learning models on SageMaker.
Data productivity platform Matillion announced a number of integrations with technical partners. Most of these integrations are accelerators that speed up some aspect of data processing between Matillion and its partners. FHIR Data, built by Matillion and Hakkoda, is a Snowflake healthcare data integrator that simplifies the process of loading FHIR data in Snowflake, then transforming it into a structured format for analytics processing. AWS Redshift Serverless Scale will let mutual Matillion-AWS customers run analytics without needing to manually provision or manage data warehouse clusters. Matillion One Click within AllCloud automates the setup and maintenance of data pipelines. Finally, the Matillion-Collibra integration creates data lineage, mapping inbound and outbound data flows, and attaches data objects to assets in the Collibra data catalog.
Analytics engine Starburst launched new capabilities for Starburst Galaxy, the managed service version of its primary Starburst Enterprise offering. The new Data Products capabilities include a catalog explorer for users to search through their data more easily and understand what they have; schema discovery, which can help users find new datasets regardless of their storage format; and enhanced security and access controls.
Starburst also announced support for AWS Lake Formation via Starburst Enterprise, which will allow joint customers to more easily implement a data mesh framework across all of an organization’s data sources.
Yesterday, IBM filed suit against Micro Focus for claims of copying part of the z/OS for data mapping in the web services implementation of Micro Focus Enterprise Suite. To understand this suit, I think the most relevant excerpts of claims in the suit are:
26. CICS® TS (Customer Information Control System Transaction Server) Web Services uses a “web service binding file,” known as a WSBIND file, to expose CICS® TS programs as web services and maps data received.
40. Micro Focus’s Enterprise Suite offers a web services implementation (“Micro Focus Web Services”) that includes a WSBIND file for mapping data • Micro Focus’s WSBIND file uses IBM internal structures that are not available outside of IBM. • The Micro Focus utility processing reflected in the log file exhibits the same configuration, program sequence, program elements, program optimizations, defects, and missing features as the corresponding CICS® TS utility programs. • Micro Focus’s WSBIND file is encoded in EBCDIC—like IBM’s—yet, Micro Focus has no need for using that encoding as it uses an ASCII environment.
(Analyst’s note: I think this is probably going to be one of the key hinges of the lawsuit. EBCDIC is really an IBM-specific format at this point while ASCII is everywhere. A bit weird to use IBM’s specific encoding for characters.)
42. …no legitimate reason for Micro Focus to have copied IBM’s computer program. Without copying from IBM, Micro Focus had a broad range of design and architectural choices that would have allowed it to create software that offers the same features as the Micro Focus Enterprise Suite.
It’s no secret that IBM has bet the farm on modernization and digital transformation (see Red Hat). The ability to manage IBM customer technology evolution is core to the future of the business. If nothing else, this suit sends a strong message: Don’t Mess with the zSeries. I’m interested to see how this suit will reference Google vs. Oracle: this isn’t the same, but I’d imagine Micro Focus will try to make it sound that way.
Editorial note: While Twitter and Meta aren’t precisely on the BI to AI spectrum per se, given the sheer prevalence and use of these massive data sources and the fast-moving news around layoffs and security issues for these properties lately, Amalgam Insights would recommend confirming that you are performing backups of relevant data on a regular schedule; that you are taking available security precautions including the use of two-factor authentication where possible; and that your communications strategies are nimble enough to respond to issues of impersonation.
Spreadsheet data automation company Coefficient has raised an $18M A round. Battery Ventures led the funding round, with participation from existing investors Foundation Capital and S28 Capital. Coefficient will use the money to scale up global operations and expand its offerings.
Strategic investment firm Databricks Ventures has taken an equity stake for an undisclosed sum in Databricks partner Matillion, a data integration solution. In doing so, Databricks extends their existing partnership with Matillion, providing financial support for Matillion’s Data Productivity cloud and how it works with Databricks’ Lakehouse Platform.
Decision intelligence platform Tellius announced version 4.0 on Wednesday. Key new features include Multi-Business View Vizpads, allowing users to view and analyze across multiple data sources without needing to constantly switch between individual dashboards for each; an enhanced onboarding and ongoing user experience with walkthroughs and in-app chat; and more robust search functionality.
Graph data platform Neo4J made Neo4J 5, the next version of its cloud-ready graph database, generally available earlier this week. Among the notable improvements: new syntax making complex queries easier to write; query performance improvements by up to 1000x; automatic scaleout to handle sudden massive bursts of query activity; and the debut of Neo4J Ops Manager to monitor and manage continuous updates across global deployments.
Anaconda made two partnership announcements this week. First, Anaconda is collaborating with Domino Data Lab to incorporate the Anaconda repository into Domino’s Enterprise MLOps Platform. Domino users will be able to access Anaconda’s Python and R packages without requiring a separate Anaconda enterprise license.
Second, Snowpark for Python, the Anaconda repository and package manager within Snowflake Data Cloud, has entered public preview. Snowflake users will be able to use Python to build data science workflows and data pipelines within Snowpark.
On a related note, dbt Labs also announced support for data transformation in Python to dbt, allowing dbt customers to take advantage of Python capabilities on major cloud data platforms such as Snowflake. Joint dbt and Snowflake customers will be able to use Python capabilities for both analytics and data science projects on Snowpark.
Data management and analytics consulting firm Sagence has been acquired by PwC, adding to PwC’s existing data strategy and digital transformation capabilities. Sagence provides additional expertise and experience in creating action plans for proposed data strategies.