This Week in Enterprise Tech, brought to you by the DX Report’s Charles Araujo and Amalgam Insights’ Hyoun Park, explores six big topics for CIOs across innovation, the value of data, strategic budget management, succession planning, and enterprise AI.
1) We start with the City of Birmingham, which is struggling with its SAP to Oracle migration. We discuss how this IT project has shifted from the promise of digital transformation to the reality of being in survival mode and the cautions of mistaking core services for innovation.
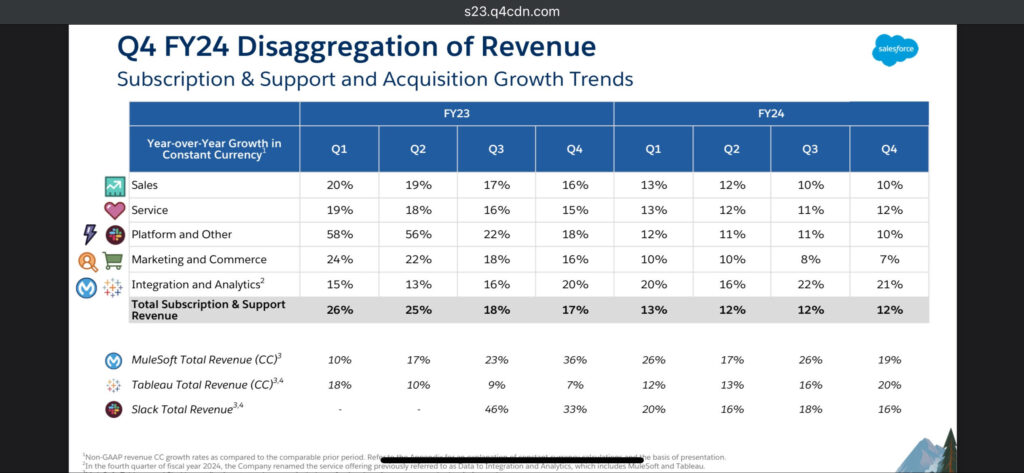
2) We then take a look at Salesforce’s earnings, where the Data Cloud is the Powerhouse of the earnings and CIOs are proving the value of data with their pocketbooks and the power of the purse. We break down the following earnings chart.
3) We saw NVIDIA’s success in AI as a sign that CIO budgets are changing. Find out about the new trend of CIO-led budgets that are independent of the traditional IT budget, as well as Charles’ framework of separating the efficiency bucket from the innovation bucket from his first book, The Quantum Age of IT.
4) One of the hottest companies in enterprise software sees a big leadership change, as Frank Slootman steps down from Snowflake and Sridhar Ramaswamy from the Neeva acquisition takes over. We discuss why this is a good move to avoid stagnation and discuss how to deal with bets in innovation.
5) Continuing the trend of innovation management, we talk about what Apple’s exit of the electric car business means in terms of managing innovative moonshots and what CIO’s often miss in terms of setting metrics around leadership and innovation culture.
6) And finally, we talk about the much-covered Google Gemini AI mistakes. We think the errors themselves fall within the range of issues that we’ve seen from other large language models, but we caution why the phrase “Eliminate Bias” should be a massive red flag for AI projects.
In Week 2 of TWIET, Charles Araujo and Amalgam Insights’ Hyoun Park take on the following topics and why they matter to the CIO Office.
This Week in Enterprise Tech, Week 2
First, we discuss the emergence of the AI app layer and what this means for enterprise IT organizations. It is not enough to simply think of AI in terms of what models are being used, but also the augmentation, tuning, app interface, maintenance, and governance of AI in the enterprise.
Second, we dig into KKR’s $3.8 billion acquisition of VMware’s End User Computing business and what this means both for the EUC business and for VMware customers as a whole as the market leader in virtualization is now owned by one of the best money makers in the tech industry, Hock Tan of Broadcom.
Third, we explore NVIDIA’s quarterly earnings by going beyond the obvious growth of data center sales of GPUs. What do the rest of NVIDIA’s sales say about the current state of Cloud FinOps and compute investments in areas such as gaming and smart autos?
And finally, we consider the nature of trust on the internet based on a recent Wired report that explores the use of robots.txt. You probably best know this file as a tool to keep Google from caching your site. But what does it mean as more and more spiders seek to automate the caching of all your web-accessible intellectual property?
Today, we are kicking off a new podcast with our Chief Analyst Hyoun Park and The DX Report’s Charles Araujo. Together, we are looking at the biggest events in enterprise technology and discussing how they affect the CIO’s office. We’re planning to bring our decades of experience as market observers, hands-on technical skills, and strategic advisors not only to show what the big stories were, but also the big lessons that IT and other technical executives need to take from these stories.
If you want to learn how to avoid the biggest mistakes that CIOs will make across strategy, succession planning, innovation, budgeting, and integrating AI into existing technology environments, subscribe to our new video and podcast efforts! Check out Week 1 right here.
This week, we discuss in this episode the philosophy of fast-rising Zoho, an enterprise application company that has grown over 10x over the past decade to become a leading CRM and analytic software provider on a global basis based on our recent visit to Zoho’s Analyst Event in McAllen, Texas. Find out how “transnational localism” has supported Zoho’s global rocket-ship growth and what it means for managing your own international team.
We then TWIET about the Apple Vision Pro and how Apple, Meta, Microsoft, and Google have been pushing the boundaries of extended reality over the past decade as well as what this means for enterprise IT organizations based on Apple’s track record.
And finally we confront the complexities of Cloud FinOps and managing cloud costs at a time when layoffs are common in the tech world and IT economics and financial management are becoming increasingly complex.
The past week has been “Must See TV” in the tech world as AI darling OpenAI provided a season of Reality TV to rival anything created by Survivor, Big Brother, or the Kardashians. Although I often joke that my professional career has been defined by the well-known documentaries of “The West Wing,” “Pitch Perfect,” and “Sillcon Valley,” I’ve never been a big fan of the reality TV genre as the twist and turns felt too contrived and over the top… until now.
Starting on Friday, November 17th, when The Real Housewives of OpenAI started its massive internal feud, every organization working on an AI project has been watching to see what would become of the overnight sensation that turned AI into a household concept with the massively viral ChatGPT and related models and tools.
So, what the hell happened? And, more importantly, what does it mean for the organizations and enterprises seeking to enter the Era of AI and the combination of generative, conversational, language-driven, and graphic capabilities that are supported with the multi-billion parameter models that have opened up a wide variety of business processes to natural language driven interrogation, prioritization, and contextualization?
The Most Consequential Shake Up In Technology Since Steve Jobs Left Apple
The crux of the problem: OpenAI, the company we all know as the creator of ChatGPT and the technology provider for Microsoft’s Copilots, was fully controlled by another entity, OpenAI, the nonprofit. This nonprofit was driven by a mission of creating general artificial intelligence for all of humanity. The charter starts with“OpenAI’s mission is to ensure that artificial general intelligence (AGI) – by which we mean highly autonomous systems that outperform humans at most economically valuable work – benefits all of humanity. We will attempt to directly build safe and beneficial AGI, but will also consider our mission fulfilled if our work aids others to achieve this outcome.”
There is nothing in there about making money. Or building a multi-billion dollar company. Or providing resources to Big Tech. Or providing stakeholders with profit other than highly functional technology systems. In fact, further in the charter, it even states that if a competitor shows up with a project that is doing better at AGI, OpenAI commits to “stop competing with and start assisting this project.”
So, that was the primary focus of OpenAI. If anything, OpenAI was built to prevent large technology companies from being the primary force and owner of AI. In that context, four of the six board members of OpenAI decided that open AI‘s efforts to commercialize technology were in conflict with this mission, especially with the speed of going to market, and the shortcuts being made from a governance and research perspective.
As a result, they ended up firing both the CEO, Sam, Altman and removed President COO Greg Brockman, who had been responsible for architecting that resources and infrastructure associated with OpenAI, from the board. That action begat this rapid mess and chaos for this 700+ employee organization which was allegedly about to see an 80 billion dollar valuation
A Convoluted Timeline For The Real Housewives Of Silicon Valley
Friday: OpenAI’s board fires its CEO and kicks its president Greg Brockman off the board. CTO Mira Murati, who was called the night before, was appointed temporary CEO. Brockman steps down later that day.
Saturday: Employees are up in arms and several key employees leave the company, leading to immediate action by Microsoft going all the way up to CEO Satya Nadella to basically ask “what is going on? And what are you doing with our $10 billion commitment, you clowns?!” (Nadella probably did not use the word clowns, as he’s very respectful.)
Sunday: Altman comes in the office to negotiate with Microsoft and OpenAI’s investors. Meanwhile, OpenAI announces a new CEO, Emmett Shear, who was previously the CEO of video game streaming company Twitch. Immediately, everyone questions what he’ll actually be managing as employees threaten to quit, refuse to show up to an all-hands meeting, and show Altman overwhelming support on social media. A tumultuous Sunday ends with an announcement by Microsoft that Altman and Brockman will lead Microsoft’s AI group.
Monday: A letter shows up asking the current board to resign with over 700 employees threatening to quit and move to the Microsoft subsidiary run by Altman and Brockman. Co-signers include board member and OpenAI Ilya Sutskever, who was one of the four board votes to oust Altman in the first place.
Tuesday: The new CEO of OpenAI, Emmett Shear, states that he will quit if the OpenAI board can’t provide evidence of why they fired Sam Altman. Late that night, Sam Altman officially comes back to OpenAI as CEO with a new board consisting initially of Bret Taylor, former co-CEO of Salesforce, Larry Summers (former Secretary of the Treasury), and Adam d’Angelo, one of the former board members who voted to figure Sam Altman. Helen Toner of Georgetown and Tasha McCauley, both seen as ethical altruists who were firmly aligned with OpenAI’s original mission, both step down from the board.
Wednesday: Well, that’s today as I’m writing this out. Right now, there are still a lot of questions about the board, the current purpose of OpenAI, and the winners and losers.
Keep In Mind As We Consider This Wild And Crazy Ride
OpenAI was not designed to make money. Firing Altman may have been defensible from OpenAI’s charter perspective to build safe General AI for everyone and to avoid large tech oligopolies. But if that’s the case, OpenAI should not have taken Microsoft’s money. OpenAI wanted to have its cake and eat it as well with a board unused to managing donations and budgets at that scale.
Was firing Altman even the right move? One could argue that productization puts AI into more hands and helps prepare society for an AGI world. To manage and work with superintelligences, one must first integrate AI into one’s life and the work Altman was doing was putting AI into more people’s hands in preparation for the next stage of global access and interaction with superintelligence.
At the same time, the vast majority of current OpenAI employees are on the for-profit side and signed up, at least in part, because of the promise of a stock-based payout. I’m not saying that OpenAI employees don’t also care about ethical AI usage, but even the secondary market for OpenAI at a multi-billion dollar valuation would help pay for a lot of mortgages and college bills. But tanking the vast majority of employee financial expectations is always going to be a hard sell, especially if they have been sold on a profitable financial outcome.
OpenAI is expensive to run: probably well over 2 billion dollars per year, including the massive cloud bill. Any attempt to slow down AI development or reduce access to current AI tools needs to be tempered by the financial realities of covering costs. It is amazing to think that OpenAI’s board was so naïve that they could just get rid of the guy who was, in essence, their top fundraiser or revenue officer without worrying about how to cover that gap.
Primary research versus go-to-market activities are very different. Normally there is a church-and-state type of wall between these two areas exactly because they are to some extent at odds with each other. The work needed to make new, better, safer, and fundamentally different technology is often conflicted with the activity used to sell existing technology. And this is a division that has been well established for decades in academia where patented or protected technologies are monetized by a separate for-profit organization.
The Effective Altruism movement: this is an important catchphrase in the world of AI, as it is not just defined as a dictionary definition. This is a catchphrase for a specific view of developing artificial general intelligence (superintelligences beyond human capacity) with the goal of supporting a population of 10^58 millennia from now. This is one extreme of the AI world, which is countered by a “doomer” mindset thinking that AI will be the end of humanity.
Practically, most of us are in between with the understanding that we have been using superhuman forces in business since the Industrial Revolution. We have been using Google, Facebook, data warehouses, data lakes, and various statistical and machine learning models for a couple of decades that vastly exceed human data and analytic capabilities.
And the big drama question for me: What is Adam d’Angelo still doing on the board as someone who actively caused this disaster to happen? There is no way to get around the fact that this entire mess was due to a board-driven coup and he was part of the coup. It would be surprising to see him stick around for more than a few months especially now that Bret Taylor is on board, who provides an overlap of experiences and capabilities that d’Angelo possesses, but at greater scale.
The 13 Big Lessons We All Learned about AI, The Universe, and Everything
First, OpenAI needs better governance in several areas: board, technology, and productization.
Once OpenAI started building technologies with commercial repercussions, the delineation between the non-profit work and the technology commercialization needed to become much clearer. This line should have been crystal clear before OpenAI took a $10 billion commitment from Microsoft and should have been advised by a board of directors that had any semblance of experience in managing conflicts of interest at this level of revenue and valuation. In particular, Adam d’Angelo as the CEO of a multi-billion dollar valued company and Helen Toner of Georgetown should have helped to draw these lines and make them extremely clear for Sam Altman prior to this moment.
Investors and key stakeholders should never be completely surprised by a board announcement. The board should only take actions that have previously been communicated to all major stakeholders. Risks need to be defined beforehand when they are predictable. This conflict was predictable and, by all accounts, had been brewing for months. If you’re going to fire a CEO, make sure your stakeholders support you and that you can defend your stance.
You come at the king, you best not miss.” As Omar said in the famed show “The Wire,” you cannot try to take out the head of an organization unless your followup plan is tight.
OpenAI’s copyright challenges feel similar to when Napster first became popular as a streaming platform for music. We had to collectively figure out how to avoid digital piracy while maintaining the convenience that Napster provided for supporting music and sharing other files. Although the productivity benefits make generative AI worth experimenting with, always make sure that you have a back up process or capability for anything supported with generative AI.
OpenAI and other generative AI firms have also run into challenges regarding the potential copyright issues associated with their models. Although a number of companies are indemnifying clients from damages associated with any outputs associated with their models, companies will likely still have to stop using any models or outputs that end up being associated with copyrighted material.
From Amalgam Insights’ perspective, the challenge with some foundational models is that training data is used to build the parameters or modifiers associated with a model. This means that the copyrighted material is being used to help shape a product or service that is being offered on a commercial basis. Although there is no legal precedent either for or against this interpretation, the initial appearance of this language fits with the common sense definitions of enforcing copyright on a commercial basis. This is why the data collating approach that IBM has taken to generative AI is an important differentiator that may end up being meaningful.
Don’t take money if you’re not willing to accept the consequences. This is a common non-profit mistake to accept funding and simply hope it won’t affect the research. But the moment research is primarily dependent on one single funder, there will always be compromises. Make sure those compromises are expressly delineated in advance and if the research is worth doing under those circumstances.
Licensing nonprofit technologies and resources should not paralyze the core non-profit mission. Universities do this all the time! Somebody at OpenAI, both in the board and at the operational level, should be a genius at managing tech transfer and commercial utilization to help avoid conflicts between the two institutions. There is no reason that the OpenAI nonprofit should be hamstrung by the commercialization of its technology because there should be a structure in place to prevent or minimize conflicts of interest other than firing the CEO.
Second, there are also some important business lessons here.
Startups are inherently unstable. Although OpenAI is an extreme example, there are many other more prosaic examples of owners or boards who are unpredictable, uncontrollable, volatile, vindictive, or otherwise unmanageable in ways that force businesses to close up shop or to struggle operationally. This is part of the reason that half of new businesses fail within five years.
Loyalty matters, even in the world of tech. It is remarkable that Sam Altman was backed by over 90% of his team on a letter saying that they would follow him to Microsoft. This includes employees who were on visas and were not independently rich, but still believed in Sam Altman more than the organization that actually signed their paychecks. Although it never hurts to also have Microsoft’s Kevin Scott and Satya Nadella in your corner and to be able to match compensation packages, this also speaks to the executive responsibility to build trust by creating a better scenario for your employees than others can provide. In this Game of Thrones, Sam Altman took down every contender to the throne in a matter of hours.
Microsoft has most likely pulled off a transaction that ends up being all but an acquisition of OpenAI. It looks like Microsoft will end up with the vast majority of OpenAI’s‘s talent as well as an unlimited license to all technology developed by OpenAI. Considering that OpenAI was about to support a stock offering with an $80 billion market cap, that’s quite the bargain for Microsoft. In particular, Bret Taylor’s ascension to the board is telling as his work at Twitter was in the best interests of the shareholders of Twitter in accepting and forcing an acquisition that was well in excess of the publicly-held value of the company. Similarly, Larry Summers, as the former president of Harvard University, is experienced in balancing non-profit concerns with the extremely lucrative business of Harvard’s endowment and intellectual property. As this board is expanded to as many as nine members, expect more of a focus on OpenAI as a for-profit entity.
With Microsoft bringing OpenAI closer to the fold, other big tech companies that have made recent investments in generative AI now have to bring those partners closer to the core business. Salesforce, NVIDIA, Alphabet, Amazon, Databricks, SAP, and ServiceNow have all made big investments in generative AI and need to lock down their access to generative AI models, processors, and relevant data. Everyone is betting on their AI strategy to be a growth engine over the next five years and none can afford a significant misstep.
Satya Nadella’s handling of the situation shows why he is one of the greatest CEOs in business history. This weekend could have easily been an immense failure and a stock price toppling event for Microsoft. But in a clutch situation, Satya Nadella personally came in with his executive team to negotiate a landing for openAI, and to provide a scenario that would be palatable both to the market and for clients. The greatest CEOs have both the strategic skills to prepare for the future and the tactical skills to deal with immediate crisis. Nadella passes with flying colors on all accounts and proves once again that behind the velvet glove of Nadella’s humility and political savvy is an iron fist of geopolitical and financial power that is deftly wielded.
Carefully analyze AI firms that may have similar charters for supporting safe AI, and potentially slowing down or stopping product development for the sake of a higher purpose. OpenAI ran into challenges in trying to interpret its charter, but the charter’s language is pretty straightforward for anyone who did their due diligence and took the language seriously. Assume that people mean what they say. Also, consider that there are other AI firms that have similar philosophies to OpenAI, such as Anthropic, which spun off of OpenAI for reasons similar to the OpenAI board reasoning of firing Sam Altman. Although it is unlikely that Anthropic (or large firms with safety-first philosophies like Alphabet and Meta’s AI teams) will fall apart similarly, the charters and missions of each organization should be taken into account in considering their potential productization of AI technologies.
AI is still an emerging technology. Diversify, diversify, diversify. It is important to diversify your portfolio and make sure that you were able to duplicate experiments on multiple foundation models when possible. The marginal cost of supporting duplicate projects pales in comparison to the need to support continuity and gain greater understanding of the breath of AI output possibilities. With the variety of large language models, software vendor products, and machine learning platforms on the market, this is a good time to experiment with multiple vendors while designing process automation and language analysis use cases.
Over the past year, Generative AI has taken the world by storm as a variety of large language models (LLMs) appeared to solve a wide variety of challenges based on basic language prompts and questions.
A partial list of market-leading LLMs currently available include:
The biggest question regarding all of these models is simple: how to get the most value out of them. And most users fail because they are unused to the most basic concept of a large language model: they are designed to be linguistic copycats.
As Andrej Karpathy of OpenAI stated earlier this year,
And we all laughed at the concept for being clever as we started using tools like ChatGPT, but most of us did not take this seriously. If English really is being used as a programming language, what does this mean for the prompts that we use to request content and formatting?
I think we haven’t fully thought out what it means for English to be a programming language either in terms of how to “prompt” or ask the model how to do things correctly or how to think about the assumptions that an LLM has as a massive block of text that is otherwise disconnected from the real world and lacks the sensory input or broad-based access to new data that can allow it to “know” current language trends.
Here are 8 core language-based concepts to keep in mind when using LLMs or considering the use of LLMs to support business processes, automation, and relevant insights.
1) Language and linguistics tools are the relationships that define the quality of output: grammar, semantics, semiotics, taxonomies, and rhetorical flourishes. There is a big difference between asking for “write 200 words on Shakespeare” vs. “elucidate 200 words on the value of Shakespeare as a playwright, as a poet, and as a philosopher based on the perspective on Edmund Malone and the English traditions associated with blank verse and iambic pentameter as a preamble to introducing the Shakespeare Theatre Association.”
I have been a critic of the quality that LLMs provide from an output perspective, most recently in my perspective “Instant Mediocrity: A Business Guide to ChatGPT in the Enterprise.” https://amalgaminsights.com/2023/06/06/instant-mediocrity-a-business-guide-to-chatgpt-in-the-enterprise/. But I readily acknowledge that the outputs one can get from LLMs will improve. Expert context will provide better results than prompts that lack subject matter knowledge
2) Linguistic copycats are limited by the rules of language that are defined within their model. Asking linguistic copycats to provide language formats or usage that are not commonly used online or in formal writing will be a challenge. Poetic structures or textual formats referenced must reside within the knowledge of the texts that the model has seen. However, since Wikipedia is a source for most of these LLMs, a contextual foundation exists to reference many frequently used frameworks.
3) Linguistic copycats are limited by the frequency of vocabulary usage that they are trained on. It is challenging to get an LLM to use expert-level vocabulary or jargon to answer prompts because the LLM will typically settle for the most commonly used language associated with a topic rather than elevated or specific terms.
This propensity to choose the most common language associated with a topic makes it difficult for LLM-based content to sound unique or have specific rhetorical flourishes without significant work from the prompt writer.
4) Take a deep breath and work on this. Linguistic copycats respond to the scope, tone, and role mentioned in a prompt. A recent study found that, across a variety of LLM’s, the prompt that provided the best answer for solving a math problem and providing instructions was not a straightforward request such as “Let’s think step by step,” but “Take a deep breath and work on this problem step-by-step.”
Using a language-based perspective, this makes sense. The explanations of mathematical problems that include some language about relaxing or not stressing would likely be designed to be more thorough and make sure the reader was not being left behind at any step. The language used in a prompt should represent the type of response that the user is seeking.
5) Linguistic copycats only respond to the prompt and the associated prompt engineering, custom instructions, and retrieval data that they can access. It is easy to get carried away with the rapid creation of text that LLM’s provide and mistake this for something resembling consciousness, but the response being created is a combination of grammatical logic and the computational ability to take billions of parameters into account across possibly a million or more different documents. This ability to access relationships across 500 or more gigabytes of information is where LLMs do truly have an advantage over human beings.
6) Linguistic robots can only respond based on their underlying attention mechanisms that define their autocompletion and content creation responses. In other words, linguistic robots make judgment calls on which words are more important to focus on in a sentence or question and use that as the base of the reply.
For instance, in the sentence “The cat, who happens to be blue, sits in my shoe,” linguistic robots will focus on the subject “cat” as the most important part of this sentence. The cat “happens to be,” implies that this isn’t the most important trait. The cat is blue. The cat sits. The cat is in my shoe. The words include an internal rhyme and are fairly nonsensical. And then the next stage of this process is to autocomplete a response based on the context provided in the prompt.
7) Linguistic robots are limited by a token limit for inputs and outputs. Typically, a token is about four characters while the average English content word is about 6.5 characters (https://core.ac.uk/download/pdf/82753461.pdf). So, when an LLM talks about supporting 2048 tokens, that can be seen as about 1260 words, or about four pages of text, for concepts that require a lot of content. In general, think of a page of content as being about 500 tokens and a minute of discussion typically being around 200 tokens when one is trying to judge how much content is either being created or entered into an LLM.
8) Every language is dynamic and evolves over time. LLMs that provide good results today may provide significantly better or worse results tomorrow simply because language usage has changed or because there are significant changes in the sentiment of a word. For instance, the English language word “trump” in 2015 has a variety of political relationships and emotional associations that are now standard to language usage in 2023. Be aware of these changes across languages and time periods in making requests, as seemingly innocuous and commonly used words can quickly gain new meanings that may not be obvious, especially to non-native speakers.
Conclusion
The most important takeaway of the now-famous Karpathy quote is to take it seriously not only in terms of using English as a programming language to access structures and conceptual frameworks, but also to understand that there are many varied nuances built into the usage of the English language. LLM’s often incorporate these nuances even if those nuances haven’t been directly built into models, simply based on the repetition of linguistic, rhetorical, and symbolic language usage associated with specific topics.
From a practical perspective, this means that the more context and expertise provided in asking an LLM for information and expected outputs, the better the answer that will typically be provided. As one writes prompts for LLMs and seek the best possible response, Amalgam Insights recommends providing the following details in any prompt:
Tone, role, and format: This should include a sentence that shows, by example, the type of tone you want. It should explain who you are or who you are writing for. And it should provide a form or structure for the output (essay, poem, set of instructions, etc…). For example, “OK, let’s go slow and figure this out. I’m a data analyst with a lot of experience in SQL, but very little understanding of Python. Walk me through this so that I can explain this to a third grader.”
Topic, output, and length: Most prompts start with the topic or only include the topic. But it is important to also include perspective on the size of the output. Example, “I would like a step by step description of how to extract specific sections from a text file into a separate file. Each instruction should be relatively short and comprehensible to someone without formal coding experience.”
Frameworks and concepts to incorporate: This can include any commonly known process or structure that is documented, such as an Eisenhower Diagram, Porter’s Five Forces, or the Overton Window. As a simpe example, one could ask, “In describing each step, compare each step to the creation of a pizza, wherever possible.”
Combining these three sections together into a prompt should provide a response that is encouraging, relatively easy to understand, and compares the code to creating a pizza.
In adapting business processes based on LLMs to make information more readily available for employees and other stakeholders, be aware of these biases, foibles, and characteristics associated with prompts as your company explores this novel user interface and user experience.
We are in a time of transformational change as the awareness of artificial intelligence (AI) grows during a time of global uncertainty. The labor supply chain is fluctuating quickly and the economy is on rocky ground as interest rates and geopolitical strife create currency challenges. Meanwhile, the commodity supply chain is in turmoil, leading to chaos and confusion. Rising interest rates and a higher cost of money are only adding to the challenges faced by those in the global business arena. In this world where technology is dominant in the business world, the global economic foundation is shifting, and the worlds of finance and talent are up for grabs, Workday stepped up to hold its AI and ML Innovation summit to show a way forward for the customers of its software platform, including a majority of the Fortune 500 that use Workday already as a system of record.
The timing of this summit will be remembered as a time of rapid AI change, with new major announcements happening daily. OpenAI’s near-daily announcements regarding working with Microsoft, launching ChatGPT, supporting plug-ins, and asking for guidance on AI governance are transforming the general public’s perception of AI. Google and Meta are racing to translate their many years of research in AI into products. Generative AI startups already focused on legal, contract, decision intelligence, and revenue intelligence use cases are happy to ride the coattails of this hype. Universities are showing how to build large language models such as Stanford’s Alpaca. And existing machine learning and AI companies such as Databricks are showing how to build custom models based on existing data for a fraction of the cost needed to build GPT.
In the midst of this AI maelstrom, Workday decided to chase the eye of the hurricane and put stakes in the ground on its current approach to innovation, AI, and ML. From our perspective, we were interested both in the executive perspective and in the product innovation associated with this Brave New World of AI.
Enter the Co-CEO – Carl Eschenbach
Workday’s AI and ML Innovation Summit commenced with an introduction of the partners and customers that would be present at the event. The Summit began with a conversation between Workday’s Co-CEOs, Aneel Bhusri and Carl Eschenbach, where Eschenbach talked about his focus on innovation and growth for the company. Eschenbach is not new to Workday, having been on its board during his time at Sequoia Capital, where he also led investments in Zoom, UIPath, and Snowflake. Having seen his work at VMware, Amalgam Insights was interested to see Eschenbach take this role and help Workday evolve its growth strategy from an executive level. From the start, both Bhusri and Eschenbach made it clear that this Co-CEO team is intended to be a temporary status with Eschenbach taking the reins in 2024, while Bhusri becomes the Executive Chair of Workday.
Eschenbach emphasized in this session that Workday has significant opportunities in providing a full platform solution, and its international reach requires additional investment both in technology and go-to-market efforts. Workday partners are essential to the company’s success and Eschenbach pointed out a recent partnership with Amazon to provide Workday as a private offering that can use Amazon Web Service contract dollars to purchase Workday products once the work is scoped by Workday. Workday executives also mentioned the need for consolidation, which is one of Amalgam Insights’ top themes and predictions for enterprise software for 2023. The trend in tech is shifting toward best-in-suite and strategic partnering opportunities rather than a scattered best-in-breed approach that may sprawl across tens or even hundreds of vendors.
These Co-CEOs also explored what Workday was going to become over the next three to five years to take the next stage of its development after Bhusri evolved Workday from an HR platform to a broader enterprise software platform. Bhusri sees Workday as a system of record that uses AI to serve customer pain points. He poses that ERP is an outdated term, but that Workday is currently categorized as a “services ERP” platform in practice when Workday is positioned as a traditional software vendor. Eschenbach adds that Workday is a management platform across people and finances on a common multi-tenant platform.
From Amalgam Insights’ perspective, this is an important positioning as Workday is establishing that its focus is on two of the highest value and highest cost issues in the company: skills and money. Both must exist in sufficient quantities and quality for companies to survive.
The Future of AI and Where Workday Fits
We then heard from Co-President Sayan Chakraborty, who took the stage to discuss the “Future of Work” across machine learning and generative AI. As a member of the National Artificial Intelligence Advisory Committee, the analysts in the audience expected Chakraborty to have a strong mastery of the issues and challenges Workday faced in AI and this expectation was clarified by the ensuing discussion.
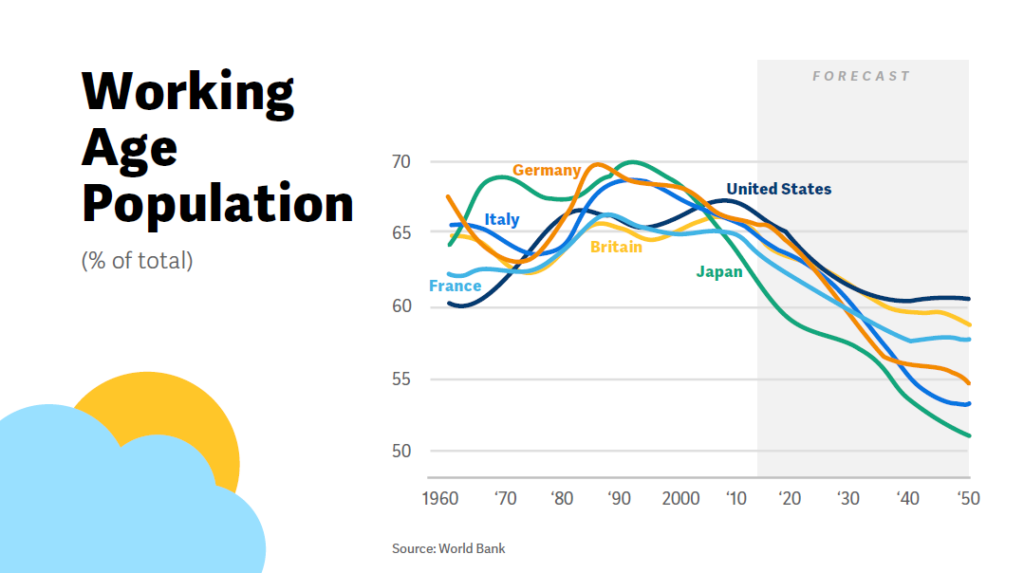
Chakraborty started by saying that Workday is monomaniacally focused on machine learning to accelerate work and points out that we face a cyclical change in the nature of the working age across the entire developed world. As we deal with a decline in the percentage of “working-age” adults on a global scale, machine learning exists as a starting point to support structural challenges in labor structures and work efforts.
To enable these efforts, Chakraborty brought up the technology, data, and application platforms based on a shared object model, starting with the Workday Cloud Platform and including analytics, Workday experience, and machine learning as specific platform capabilities. Chakraborty referenced the need for daily liquidity FDIC requests as a capability that is now being asked for in light of banking failures and stresses such as the recent Silicon Valley Bank failure.
Workday has four areas of differentiation in machine learning: data management, autoML (automated machine learning, including feature abstraction), federated learning, as well as a platform approach. Workday’s advantage in data is stated across quantity, quality associated with a single data model, structure and tenancy, and the amplification of third-party data. As a starting point, this approach allows Workday to support models based on regional or customer-specific data supported by transfer learning. At this point, Chakraborty was asked why Workday has Prism in a world of Snowflake and other analytic solutions capable of scrutinizing data and supporting analytic queries and data enrichment. Prism is currently positioned as an in-platform capability that allows Workday to enrich its data, which is a vital capability as companies face the battle for context across data and analytic outputs.
Amalgam Insights will dig into this in greater detail in our recommendations and suggestions, but at this point we’ll note that this set of characteristics is fairly uncommon at the global software platform level and presents opportunities to execute based on recent AI announcements that Workday’s competitors will struggle to execute on.
Workday currently supports federated machine learning at scale out to the edge of Workday’s network, which is part of Workday’s differentiation in providing its own cloud. This ability to push the model out to the edge is increasingly important for supporting geographically specific governance and compliance needs (dubbed by some as the “Splinternet“) as Workday has seen increased demand for supporting regional governance requests leading to separate US and European Union machine learning training teams each working on regionally created data sources.
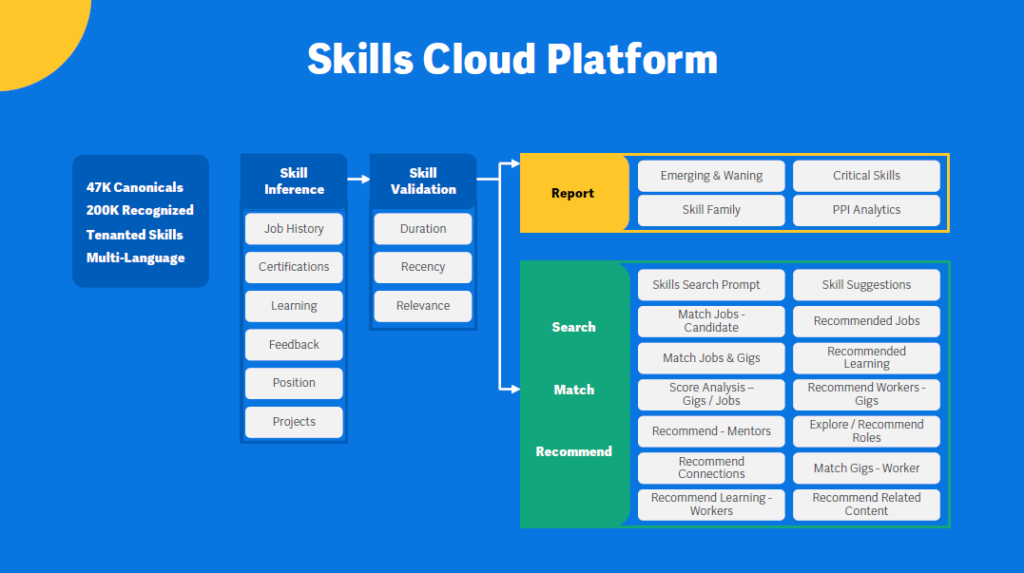
Chakraborty compared Workday’s approach of a platform machine learning approach leading to a variety of features to traditional machine learning feature-building approaches where each feature is built through a separate data generation process. The canonical Workday example is Workday’s Skills Cloud platform where Workday currently has close to 50,000 canonical skills and 200,000 recognized skills and synonyms scored for skill strength and validity. This Skills Cloud is a foundational differentiator for Workday and one that Amalgam Insights references regularly as an example of a differentiated syntactic and semantic layer of metadata that can provide differentiated context to a business trying to understand why and how data is used.
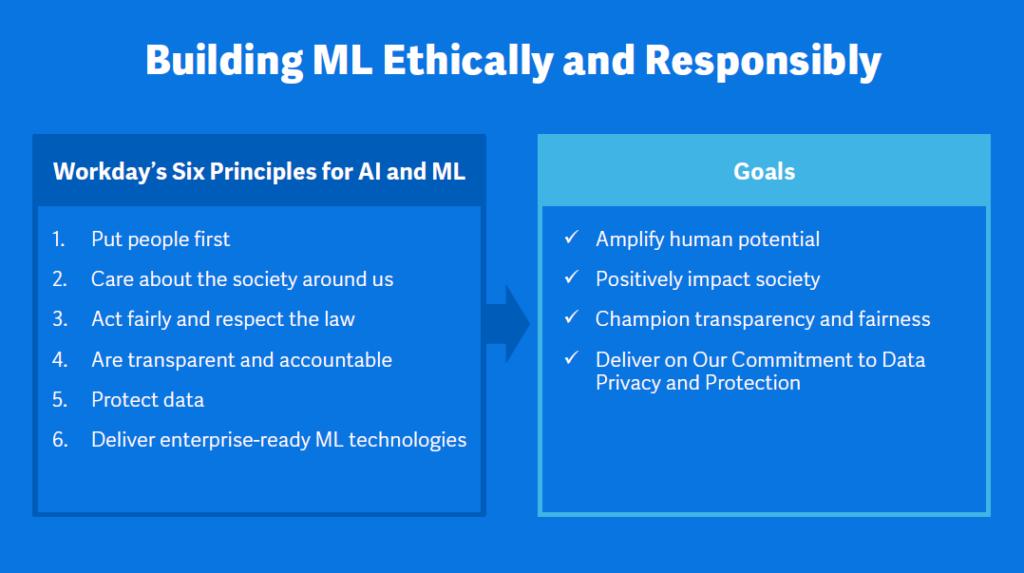
Workday mentioned six core principles for AI and ML, including people and customers, built to ensure that the machine learning capabilities developed are done through ethical approaches. In this context, Chakraborty also mentioned generative AI and large language models, which are starting to provide human-like outputs across voice, art, and text. He points out how the biggest change in AI occurred in 2006 when NVIDIA created GPUs, which used matrix math to support the constant re-creation of images. Once GPUs were used from a computational perspective, they made massively large parameter models possible. Chakraborty also pointed out the 2017 DeepMind paper on transformers to solve problems in parallel rather than sequentially, which led to the massive models that could be supported by cloud models. The 1000x growth in two years is unprecedented even from a tech perspective. Models have reached a level of scale where they can solve emergent challenges that they have not been trained on. This does not imply consciousness but does demonstrate the ability to analyze complex patterns and systems behavior. Amalgam Insights notes that this reflects a common trend in technology where new technology approaches often take a number of years to come to market, only to be treated as instant successes once they reach mainstream adoption.
Chakraborty points out that the weaknesses of GPT include bad results and a lack of explainability in machine learning, bad actors (including IP and security concerns), and the potential Environmental, Social, and Governance costs associated with financial, social, and environmental concerns. As with all technology, GPT and other generative AI models take up a lot of energy and resources without any awareness of how to throttle down in a sustainable and still functional manner. From a practical perspective, this means that current AI systems will be challenged to manage uptime as all of these new services attempt to benchmark and define their workloads and resource utilization. These problems are especially problematic in enterprise technology as the perceived reliability of enterprise software is often based on near-perfect accuracy of calculating traditional data and analytic outputs.
Amalgam Insights noted in our review of ChatGPT that factual accuracy and intellectual property attribution have been largely missing in recent AI technologies that have struggled to understand or contextualize a question based on surroundings or past queries. The likes of Google and Meta have focused on zero-shot learning for casual identification of trends and images rather than contextually specific object identification and topic governance aligned to specific skills and use cases. This is an area where both plug-ins and the work of enterprise software companies will be vital over the course of this year to augment the grammatically correct responses of generative AI with the facts and defined taxonomies used to conduct business.
Amalgam also found it interesting that Chakraborty mentioned that the future of models would include high-quality data and smaller models custom-built to industry and vertical use cases. This is an important statement because the primary discussion in current AI circles is often about how bigger is better and how models compete on having hundreds of billions of parameters to consider. In reality, we have reached the level of complexity where a well-trained model will provide responses that reflect the data that it has been trained on. The real work at this point is on how to better contextualize answers and how to separate quantitative and factual requests from textual and grammatical requests that may be in the same question. The challenge of accurate tone and grammar is very different from the ability to understand how to transform an eigenvector and get accurate quantitative output. Generative AI tends to be good at grammar but is challenged by quantitative and fact-based queries that may have answers that differ from its grammatical autocompletion logic.
Chakraborty pointed out that reinforcement learning has proven to be more useful than either supervised or unsupervised training for machine learning, as it allows models to look at user behavior rather than forcing direct user interaction. This Workday focus both provides efficacy of scale and takes advantage of Workday’s existing platform activities. This combination of reinforcement training and Workday’s ownership of its Skills Cloud will provide a sizable advantage over most of the enterprise AI world in aligning general outputs to the business world.
Amalgam Insights notes here that another challenge of the AI discussion is how to create an ‘unbiased’ approach for training and testing models when the more accurate question is to document the existing biases and assumptions that are being made. The sooner we can move from the goal of being “unbiased” to the goal of accurately documenting bias, the better we will be able to trust the AI we use.
Recommendations for the Amalgam Community on Where Workday is Headed Next
Obviously, this summit provided Amalgam Insights both with a lot of food for thought provided by Workday’s top executives. The introductory remarks summarized above were followed up with insight and guidance on Workday’s product roadmap across both the HR and finance categories where Workday has focused its product efforts, as well as visibility to the go-to-market and positioning, approaches that Workday plans to provide in 2023. Although much of these discussions were held under a non-disclosure agreement, Amalgam Insights will try to use this guidance to help companies to understand what is next from Workday and what customers should request. From an AI perspective, Amalgam Insights believes that customers should push Workday in the following areas based on Workday’s ability to deliver and provide business value.
Use the data model to both create and support large language models (LLMs). The data model is a fundamental advantage in setting up machine learning and chat interfaces. Done correctly, this is a way to have a form of Ask Me Anything for the company based on key corporate data and the culture of the organization. This is an opportunity to use trusted data to provide relevant advice and guidance to the enterprise. As one of the largest and most trusted data sources in the enterprise software world, Workday has an opportunity to quickly build, train, and deploy models on behalf of customers, either directly or through partners. With this capability, “Ask Workday” may quickly become the HR and finance equivalent of “Ask Siri.”
Use Workday’s Skills Cloud as a categorization to analyze the business, similar to cost center, profit center, geographic region, and other standard categories. Workforce optimization is not just about reducing TCO, but aligning skills, predicting succession and future success potential, and market availability for skills. Looking at the long-term value of attracting valuable skills and avoiding obsolete skills is an immense change for the Future of Work. Amalgam Insights believes that Workday’s market-leading Skills Cloud provides an opportunity for smart companies to analyze their company below the employee level and actually ascertain the resources and infrastructure associated with specific skills.
Workday still has room to improve regarding consolidation, close, and treasury management capabilities. In light of the recent Silicon Valley Bank failure and the relatively shaky ground that regional and niche banks currently are on, it’s obvious that daily bank risk is now an issue to take into account as companies check if they can access cash and pay their bills. Finance departments want to consolidate their work into one area and augment a shared version of the truth with individualized assumptions. Workday has an opportunity to innovate in finance as comprehensive vendors in this space are often outdated or rigidly customized on a per-customer level that does not allow versions to scale out in a financially responsible way as the Intelligent Data Core allows. And Workday’s direct non-ERP planning competitors mostly lack Workday’s scale both in its customer base and consultant partner relationships to provide comprehensive financial risk visibility across macroeconomic, microeconomic, planning, budgeting, and forecasting capabilities. Expect Workday to continue working on making this integrated finance, accounting, and sourcing experience even more integrated over time and to pursue more proactive alerts and recommendations to support strategic decisions.
Look for Workday Extend to be accessed more by technology vendors to create custom solutions. The current gallery of solutions is only a glimpse of the potential of Extend in establishing Workday-based custom apps. It only makes sense for Workday to be a platform for apps and services as it increasingly wins more enterprise data. From an AI perspective, Amalgam Insights would expect to see Workday Extend increasingly working with more plugins (including ChatGPT plugins), data models, and machine learning models to guide the context, data quality, hyperparameterization, and prompts needed for Workday to be an enterprise AI leader. Amalgam Insights also expects this will be a way for developers in the Workday ecosystem to take more advantage of the machine learning and analytics capabilities within Workday that are sometimes overlooked as companies seek to build models and gain insights into enterprise data.
2023 is going to be a tough year for anybody managing technology. As we face the repercussions of inflation and high interest rates and the bubble of tech starts to be burst, we are seeing a combination of hiring freezes, increased focus on core business activities and the hoary request to “do more with less.”
Behind the cliche of doing more with less is the need to actually become more efficient with tech usage. This means adopting a FinOps (Financial Operations) strategy to cloud to go with your existing Telecom FinOps (aka Telecom expense) and SaaS FinOps (aka SaaS Management) strategies. And it means being prepared for new spend category challenges as companies will need to invest in technology to get work done at a time when it is harder to hire the right person at the right time. Here is a quick preview of our predictions.
14 Key Predictions for the IT Executive in 2023
To get the details on each of these trends and predictions and understand why they matter in 2023, download this report at no cost by filling out this quick form to join our low-volume bi-monthly mailing list. (Note: If you do not wish to join our mailing list, you can alsopurchase a personal license for this report.)
2022 was a banner year for artificial intelligence technologies that reached the mainstream. After years of being frustrated with the likes of Alexa, Cortana, and Siri and the inability to understand the value of machine learning other than as a vague backend technology for the likes of Facebook and Google, 2022 brought us AI-based tools that was understandable at a consumer level. From our perspective, the most meaningful of these were two products created by OpenAI: DALL-E and ChatGPT, which expanded the concept of consumer AI from a simple search or networking capability to a more comprehensive and creative approach for translating sentiments and thoughts into outputs.
DALL-E (and its successor DALL-E 2) is a system that can create visual images based on text descriptions. The models behind DALL-E look at relationships between existing images and the text metadata that has been used to describe those images. Based on these titles and descriptions, DALL-E uses diffusion models to start with random pixels that lead to generated images based on these descriptions. This area of research is by no means unique to OpenAI, but it is novel to open up a creative tool such as DALL-E to the public. Although the outputs are often both interesting and surprisingly different from what one might have imagined, they are not without their issues. For instance, the discussion around the legal ownership of DALL-E created graphics is not clear, since Open AI claims to own the images used, but the images themselves are often based on other copyrighted images. One can imagine that, over time, an artistic sampling model may start to appear similar to the music industry where licensing contracts are used to manage the usage of copyrighted material. But this will require greater visibility regarding the lineage of AI-based content creation and the data used to support graphic diffusion. Until this significant legal question is solved, Amalgam Insights believes that the commercial usage of DALL-E will be challenging to manage. This is somewhat reminiscent of the challenges that Napster faced at the end of the 20th century as a technology that both transformed the music industry and had to deal with the challenges of a new digital frontier.
But the technology that has taken over the zeitgeist of technology users is ChatGPT and related use cases associated with the GPT (Generative Pre-Trained Transformer) autoregressive language model trained on 500 billion words across the web, Wikipedia, and books. And it has become the favorite plaything of many a technologist. What makes ChatGPT attractive is its ability to take requests from users asking questions with some level of subject matter specificity or formatting and to create responses in real-time. Here are a couple of examples from both a subject matter and creative perspective.
Example 1: Please provide a blueprint for bootstrapping a software startup.
This is a bit generic and lacks some important details on how to find funding or sell the product, but it is in line with what one might expect to see in a standard web article regarding how to build a software product. The ending of this answer shows how the autogenerative text is likely referring to prior web-based content built for search engine optimization and seeking to provide a polite conclusion based on junior high school lessons in writing the standard five-paragraph essay rather than a meaningful conclusion that provides insight. In short, it is basically a status quo average article with helpful information that should not be overlooked, but is not either comprehensive or particularly insightful for anyone who has ever actually started a business.
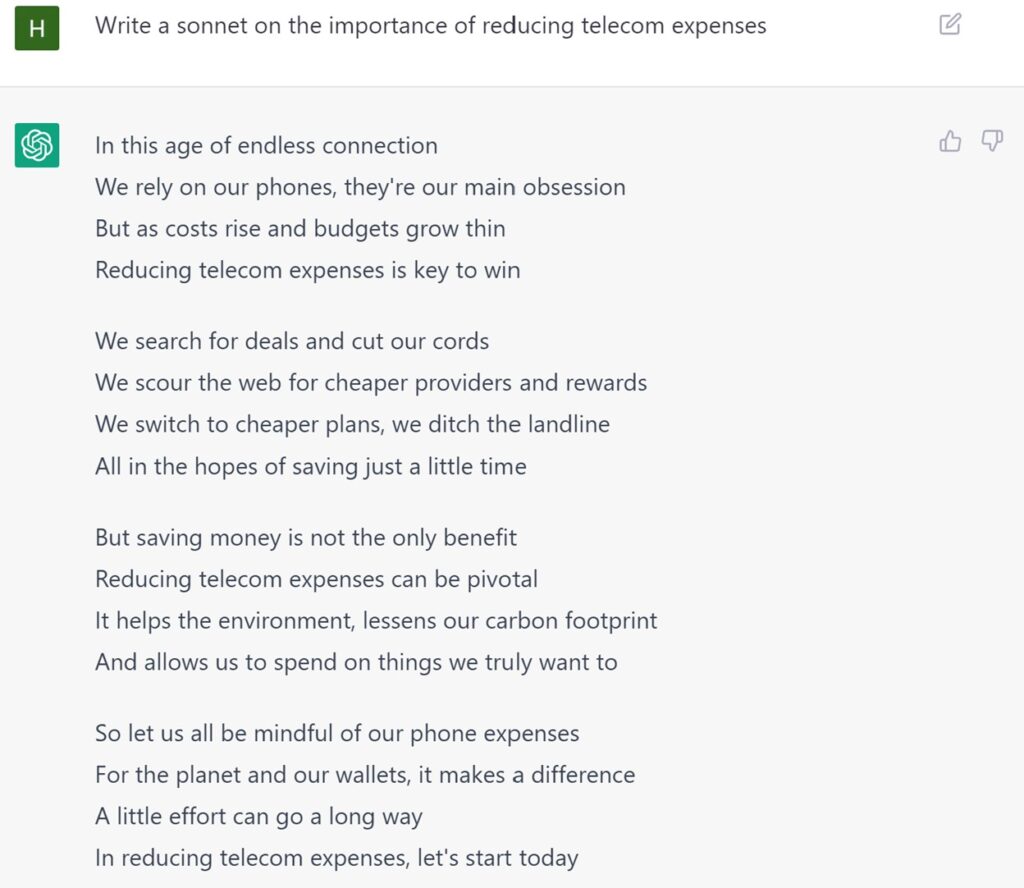
A second example of ChatGPT is in providing creative structural formats for relatively obscure topics. As you know, I’m an expert in technology expense management with over two decades of experience and one of the big issues I see is, of course, the lack of poetry associated with this amazing topic. So, again, let’s go to ChatGPT.
Example 2: Write a sonnet on the importance of reducing telecom expenses
As a poem, this is pretty good for something written in two seconds. But it’s not a sonnet, as sonnets are 14 lines, written in iambic pentameter (10 syllable lines split int 5 iambs, or a unstressed syllable followed by a stressed syllable) and split into three sections of four lines followed by a two-line section with a rhyme scheme of ABAB, CDCD, EFEF, GG. So, there’s a lot missing there.
So, based on these examples, how should ChatGPT be used? First, let’s look at what this content reflects. The content here represents the average web and text content that is associated with the topic. With 500 billion words in the GPT-3 corpus, there is a lot of context to show what should come next for a wide variety of topics. Initial concerns of GPT-3 have started with the challenges of answering questions for extremely specific topics that are outside of its training data. But let’s consider a topic I worked on in some detail back in my college days while using appropriate academic language in asking a version of Gayatri Spivak’s famous (in academic circles) question “Can the subaltern speak?”
Example 3: Is the subaltern allowed to fully articulate a semiotic voice?
Considering that the language and topic here is fairly specialized, the introductory assumptions are descriptive but not incisive. The answer struggles with the “semiotic voice” aspect of the question in discussing the ability and agency to use symbols from a cultural and societal perspective. Again, the text provides a feeling of context that is necessary, but not sufficient, to answer the question. The focus here is on providing a short summary that provides an introduction to the issue before taking the easy way out telling us what is “important to recognize” without really taking a stand. And, again, the conclusion sounds like something out of an antiseptic human resources manual in asking for the reader to consider “different experiences and abilities” rather than the actual question regarding the ability to use symbols, signs, and assumptions. This is probably enough of an analysis at a superficial level as the goal here isn’t to deeply explore postmodern semiotic theory but to test ChatGPT’s response in a specialized topic.
Based on these three examples, one should be careful in counting on ChatGPT to provide a comprehensive or definitive answer to a question. Realistically, we can expect ChatGPT will provide representative content for a topic based on what is on the web. The completeness and accuracy of a ChatGPT topic is going to be dependent on how often the topic has been covered online. The more complete an answer is, the more likely it is that this topic has already been covered in detail.
ChatGPT will provide a starting point for a topic and typically provide information that should be included to introduce the topic. Interestingly, this means that ChatGPT is significantly influenced by the preferences that have built online web text over the past decade of content explosion. The quality of ChatGPT outputs seems to be most impressive to those who treat writing as a factual exercise or content creation channel while those who look at writing as a channel to explore ideas may find it lacking for now based on its generalized model.
From a topical perspective, ChatGPT will probably have some basic context for whatever text is used in a query. It would be interesting to see the GPT-3 model augmented with specific subject matter texts that could prioritize up-to-date research, coding, policy, financial analysis, or other timely new content either as a product or training capability.
In addition, don’t expect ChatGPT to provide strong recommendations or guidance. The auto-completion that ChatGPT does is designed to show how everyone else has followed up on this topic. And, in general, people do not tend to take strong stances on web-based content or introductory articles.
Fundamentally, ChatGPT will do two things. First, it will make mediocre content ubiquitous. There is no need to hire people to write an “average” post for your website anymore as ChatGPT and other technologies either designed to compete with or augment it will be able to do this easily. If your skillset is to write grammatically sound articles with little to no subject matter experience or practical guidance, that skill is now obsolete as status quo and often-repeated content can now be created on command. This also means that there is a huge opportunity to combine ChatGPT with common queries and use cases to create new content on demand. However, in doing so, users will have to be very careful not to plagiarize content unknowingly. This is an area where, just like with DALL-E, OpenAI will have to work on figuring out data lineage, trademark and copyright infringement, and appropriation of credit to support commercial use cases. ChatGPT struggles with what are called “hallucinations” where ChatGPT makes up facts or sources because those words are physically close to the topic discussed in the various websites and books that ChatGPT uses. ChatGPT is a text generation tool that picks words based on how frequently they show up with other words. Sometimes that result will be extremely detailed and current and other times, it will look very generic and mix up related topics that are often discussed together.
Second, this tool now provides a much stronger starting point for writers seeking to say something new or different. If your point of view is something that ChatGPT can provide in two seconds, it is neither interesting or new. To stand out, you need to provide greater insight, better perspective, or stronger directional guidance. This is an opportunity to improve your skills or to determine where your professional skills lie. ChatGPT still struggles with timely analysis, directional guidance, practical recommendations beyond surface-level perspectives, and combining mathematical and textual analysis (i.e. doing word problems or math-related case studies or code review) so there is still an immense amount of opportunity for people to write better.
Ultimately, ChatGPT is a reflection of the history of written text creation, both analog and digital. Like all AI, ChatGPT provides a view of how questions were answered in the past and provides an aggregate composite based on auto-completion. For topics with a basic consensus, such as how to build a product, this tool will be an incredible time saver. For topics that may have multiple conflicting opinions, ChatGPT will try to play either both sides or all sides in a neutral manner. And for niche topics, ChatGPT will try to fake an answer at what is approximately a high school student’s understanding of the topic. Amalgam Insights recommends that all knowledge workers experiment with ChatGPT in their realm of expertise as this tool and the market of products that will be built based on the autogenerated text will play an important role in supporting the next generation of tech.
$200M F Round for Dataiku from Wellington Management This week, Wellington Management led the latest round of funding for AI stalwart Dataiku, a Series F round of $200M. DAtaiku will use the funding for continued growth and expansion of its platform capabilities.
Launches and Updates
Data Lineage Now Generally Available in Databricks Unity Catalog On December 12, Databricks announced the general availability of data lineage in their Unity Catalog governance solution, after six months of being in preview. Customers at the Databricks Premium and Enterprise tiers now have access to automatically captured data lineage at no extra cost; they will need to restart their clusters or SQL Warehouses that were last started prior to December 7.
insightsoftware Launches Jet Analytics Cloud On Monday, insightsoftware released Jet Analytics Cloud, a managed services offering of the Jet Analytics data prep and analytics tool. Jet Analytics Cloud is now available on the Azure public cloud.
MarkLogic Modernizes with Version 11 Veteran data platform MarkLogic announced MarkLogic 11 earlier this week. Key modernization features include improved support for GraphQL, OpenGIS and GeoSPARQL, and OAuth; extended capabilities for the MarkLogic Optic API; more flexible deployment and management options, including support for Docker and Kubernetes; and improved observability, auditability, and manageability capabilities.
MathWorks Debuts Modelscape for Model Management in Regulated Industries On December 15, MathWorks released Modelscape, a suite of products designed to help primarily financial institutions reduce risk during the model lifecycle while complying with regulatory requirements. The products include Modelscape Governance, which provides centralized access to models, dependencies, metadata, lineage, audit trail, risk scoring, and overall model risk reporting; Modelscape Develop, to develop models with automated documentation and reproducible processes; Modelscape Validate, to validate models; Modelscape Test, to automatically test models before putting them into production; Modelscape Deploy, to deploy models into production without recoding, with both on-prem and cloud options; and Modelscape Monitor, to monitor, analyze, and report on model performance in a dashboard scenario.
SingleStore Announces Version 8.0 SingleStore released version 8.0 of their cloud-native database this week. New capabilities include better query performance with semi-structured data such as JSON data, dynamic workspace scaling, new realtime and historical monitoring capabilities, and OAuth support.
Partnerships
Microsoft and London Stock Exchange Group Announce Long-Term Strategic Partnership Microsoft and the London Stock Exchange Group have announced a decade-long strategic partnership. LSEG’s data infrastructure will be architected on the Microsoft cloud, and both companies will co-develop new data and analytics products and services. In addition, Microsoft has agreed to purchase a 4% equity stake in LSEG by acquiring shares from the Blackstone/Thomson Reuters Consortium.
Panoply by SQream Now In the Google Cloud Marketplace Data analytics acceleration platform SQream is now available in the Google Cloud Marketplace. Panoply users will be able to purchase Panoply within GCM, then set up a Google BigQuery instance within Panoply and connect their data.
Syniti Match and Syniti Replicate Available on SAP® Store Enterprise data management company Syniti has made Syniti Match and Syniti Replicate available in the SAP Store. Syniti Match, integrated with SAP HANA, is data matching software, while Syniti Replicate provides data integration and realtime data streaming. Replicate can also integrate with both SAP HANA and SAP S/4HANA, with change data capture capability and data lake operations.
Semantic layer platform AtScale announced Thursday that it was now available on Google Cloud Marketplace. Mutual customers will be able to use AtScale on Google Cloud with services such as Google BigQuery, where they can run BI and OLAP workloads without needing to extract or move data.
Open data lakehouse Dremio announced a number of improvements this week. Among the updates: new SQL functionality, including support for the MAP data type so users can query map data from Parquet, Iceberg, and Delta Lake; security enhancements such as row and column-level policy-defined access control for users; support for INSERT, DELETE, and UPDATE on Iceberg tables, and for “time travel” to query historical data in place; as well as usability and performance improvements. Dremio also added a number of connectors, including dbt, Snowflake, MongoDB, DB2, OpenSearch, and Azure Data Explorer.
At AWS re:Invent 2022, Informatica announced three new capabilities for Informatica within AWS. Informatica Data Loader is embedded within Amazon Redshift so that mutual customers will be able to ingest data from a wide variety of systems, including AWS. The Informatica Data Marketplace now supports AWS Data Exchange, allowing customers to access and use third-party data hosted on the Data Exchange. And Informatica INFACore, INFA’s new development and data science framework, simplifies the process of developing and maintaining complex data pipelines, which can be shunted over to Amazon SageMaker Studio as a simple function, allowing users to pull prepared data from INFACore into SageMaker Studio for further use in building, training, and deploying machine learning models on SageMaker.
Data productivity platform Matillion announced a number of integrations with technical partners. Most of these integrations are accelerators that speed up some aspect of data processing between Matillion and its partners. FHIR Data, built by Matillion and Hakkoda, is a Snowflake healthcare data integrator that simplifies the process of loading FHIR data in Snowflake, then transforming it into a structured format for analytics processing. AWS Redshift Serverless Scale will let mutual Matillion-AWS customers run analytics without needing to manually provision or manage data warehouse clusters. Matillion One Click within AllCloud automates the setup and maintenance of data pipelines. Finally, the Matillion-Collibra integration creates data lineage, mapping inbound and outbound data flows, and attaches data objects to assets in the Collibra data catalog.
Analytics engine Starburst launched new capabilities for Starburst Galaxy, the managed service version of its primary Starburst Enterprise offering. The new Data Products capabilities include a catalog explorer for users to search through their data more easily and understand what they have; schema discovery, which can help users find new datasets regardless of their storage format; and enhanced security and access controls.
Starburst also announced support for AWS Lake Formation via Starburst Enterprise, which will allow joint customers to more easily implement a data mesh framework across all of an organization’s data sources.