We are in a time of transformational change as the awareness of artificial intelligence (AI) grows during a time of global uncertainty. The labor supply chain is fluctuating quickly and the economy is on rocky ground as interest rates and geopolitical strife create currency challenges. Meanwhile, the commodity supply chain is in turmoil, leading to chaos and confusion. Rising interest rates and a higher cost of money are only adding to the challenges faced by those in the global business arena. In this world where technology is dominant in the business world, the global economic foundation is shifting, and the worlds of finance and talent are up for grabs, Workday stepped up to hold its AI and ML Innovation summit to show a way forward for the customers of its software platform, including a majority of the Fortune 500 that use Workday already as a system of record.
The timing of this summit will be remembered as a time of rapid AI change, with new major announcements happening daily. OpenAI’s near-daily announcements regarding working with Microsoft, launching ChatGPT, supporting plug-ins, and asking for guidance on AI governance are transforming the general public’s perception of AI. Google and Meta are racing to translate their many years of research in AI into products. Generative AI startups already focused on legal, contract, decision intelligence, and revenue intelligence use cases are happy to ride the coattails of this hype. Universities are showing how to build large language models such as Stanford’s Alpaca. And existing machine learning and AI companies such as Databricks are showing how to build custom models based on existing data for a fraction of the cost needed to build GPT.
In the midst of this AI maelstrom, Workday decided to chase the eye of the hurricane and put stakes in the ground on its current approach to innovation, AI, and ML. From our perspective, we were interested both in the executive perspective and in the product innovation associated with this Brave New World of AI.
Enter the Co-CEO – Carl Eschenbach
Workday’s AI and ML Innovation Summit commenced with an introduction of the partners and customers that would be present at the event. The Summit began with a conversation between Workday’s Co-CEOs, Aneel Bhusri and Carl Eschenbach, where Eschenbach talked about his focus on innovation and growth for the company. Eschenbach is not new to Workday, having been on its board during his time at Sequoia Capital, where he also led investments in Zoom, UIPath, and Snowflake. Having seen his work at VMware, Amalgam Insights was interested to see Eschenbach take this role and help Workday evolve its growth strategy from an executive level. From the start, both Bhusri and Eschenbach made it clear that this Co-CEO team is intended to be a temporary status with Eschenbach taking the reins in 2024, while Bhusri becomes the Executive Chair of Workday.
Eschenbach emphasized in this session that Workday has significant opportunities in providing a full platform solution, and its international reach requires additional investment both in technology and go-to-market efforts. Workday partners are essential to the company’s success and Eschenbach pointed out a recent partnership with Amazon to provide Workday as a private offering that can use Amazon Web Service contract dollars to purchase Workday products once the work is scoped by Workday. Workday executives also mentioned the need for consolidation, which is one of Amalgam Insights’ top themes and predictions for enterprise software for 2023. The trend in tech is shifting toward best-in-suite and strategic partnering opportunities rather than a scattered best-in-breed approach that may sprawl across tens or even hundreds of vendors.
These Co-CEOs also explored what Workday was going to become over the next three to five years to take the next stage of its development after Bhusri evolved Workday from an HR platform to a broader enterprise software platform. Bhusri sees Workday as a system of record that uses AI to serve customer pain points. He poses that ERP is an outdated term, but that Workday is currently categorized as a “services ERP” platform in practice when Workday is positioned as a traditional software vendor. Eschenbach adds that Workday is a management platform across people and finances on a common multi-tenant platform.
From Amalgam Insights’ perspective, this is an important positioning as Workday is establishing that its focus is on two of the highest value and highest cost issues in the company: skills and money. Both must exist in sufficient quantities and quality for companies to survive.
The Future of AI and Where Workday Fits
We then heard from Co-President Sayan Chakraborty, who took the stage to discuss the “Future of Work” across machine learning and generative AI. As a member of the National Artificial Intelligence Advisory Committee, the analysts in the audience expected Chakraborty to have a strong mastery of the issues and challenges Workday faced in AI and this expectation was clarified by the ensuing discussion.
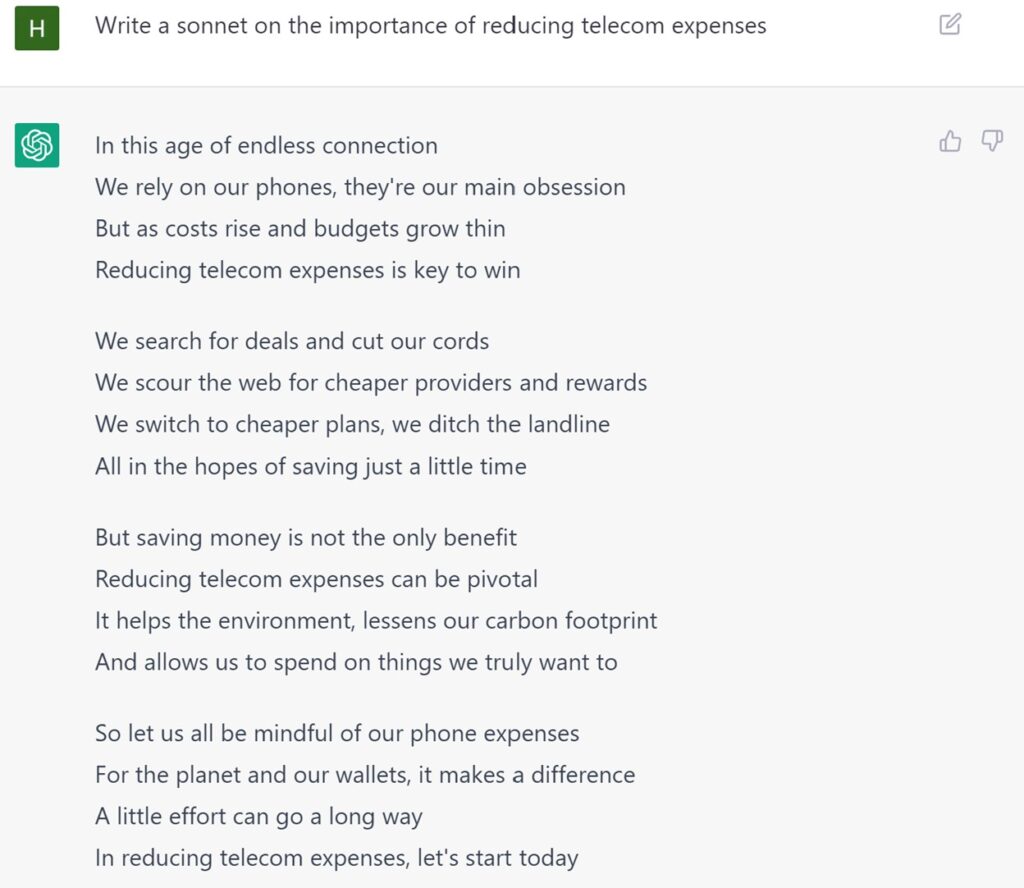
Chakraborty started by saying that Workday is monomaniacally focused on machine learning to accelerate work and points out that we face a cyclical change in the nature of the working age across the entire developed world. As we deal with a decline in the percentage of “working-age” adults on a global scale, machine learning exists as a starting point to support structural challenges in labor structures and work efforts.
To enable these efforts, Chakraborty brought up the technology, data, and application platforms based on a shared object model, starting with the Workday Cloud Platform and including analytics, Workday experience, and machine learning as specific platform capabilities. Chakraborty referenced the need for daily liquidity FDIC requests as a capability that is now being asked for in light of banking failures and stresses such as the recent Silicon Valley Bank failure.
Workday has four areas of differentiation in machine learning: data management, autoML (automated machine learning, including feature abstraction), federated learning, as well as a platform approach. Workday’s advantage in data is stated across quantity, quality associated with a single data model, structure and tenancy, and the amplification of third-party data. As a starting point, this approach allows Workday to support models based on regional or customer-specific data supported by transfer learning. At this point, Chakraborty was asked why Workday has Prism in a world of Snowflake and other analytic solutions capable of scrutinizing data and supporting analytic queries and data enrichment. Prism is currently positioned as an in-platform capability that allows Workday to enrich its data, which is a vital capability as companies face the battle for context across data and analytic outputs.
Amalgam Insights will dig into this in greater detail in our recommendations and suggestions, but at this point we’ll note that this set of characteristics is fairly uncommon at the global software platform level and presents opportunities to execute based on recent AI announcements that Workday’s competitors will struggle to execute on.
Workday currently supports federated machine learning at scale out to the edge of Workday’s network, which is part of Workday’s differentiation in providing its own cloud. This ability to push the model out to the edge is increasingly important for supporting geographically specific governance and compliance needs (dubbed by some as the “Splinternet“) as Workday has seen increased demand for supporting regional governance requests leading to separate US and European Union machine learning training teams each working on regionally created data sources.
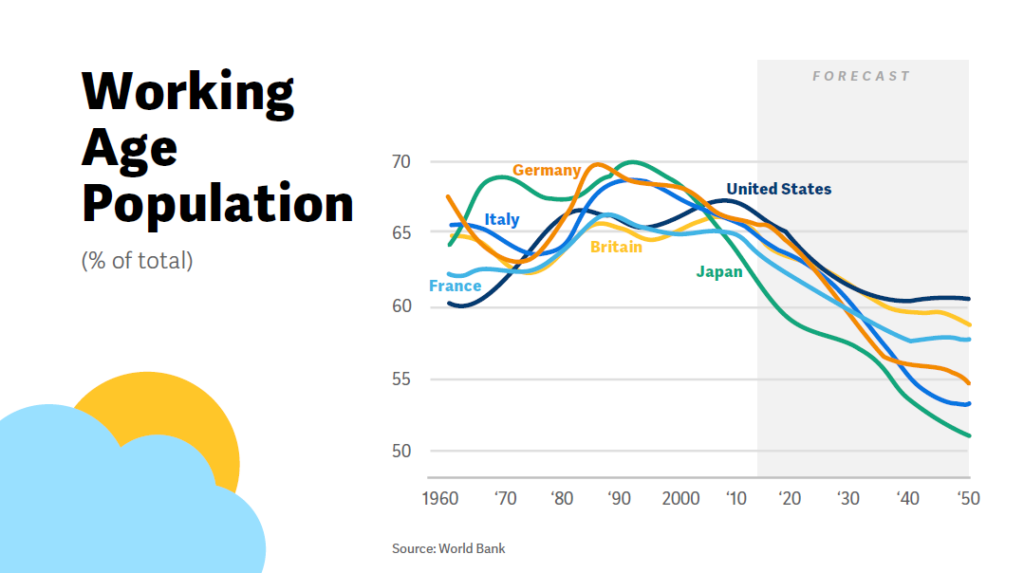
Chakraborty compared Workday’s approach of a platform machine learning approach leading to a variety of features to traditional machine learning feature-building approaches where each feature is built through a separate data generation process. The canonical Workday example is Workday’s Skills Cloud platform where Workday currently has close to 50,000 canonical skills and 200,000 recognized skills and synonyms scored for skill strength and validity. This Skills Cloud is a foundational differentiator for Workday and one that Amalgam Insights references regularly as an example of a differentiated syntactic and semantic layer of metadata that can provide differentiated context to a business trying to understand why and how data is used.
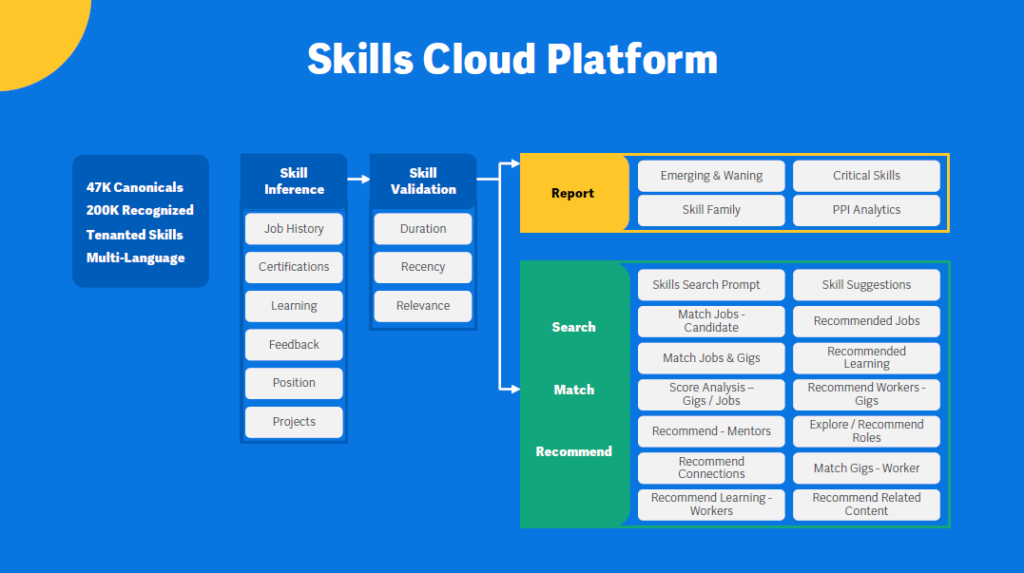
Workday mentioned six core principles for AI and ML, including people and customers, built to ensure that the machine learning capabilities developed are done through ethical approaches. In this context, Chakraborty also mentioned generative AI and large language models, which are starting to provide human-like outputs across voice, art, and text. He points out how the biggest change in AI occurred in 2006 when NVIDIA created GPUs, which used matrix math to support the constant re-creation of images. Once GPUs were used from a computational perspective, they made massively large parameter models possible. Chakraborty also pointed out the 2017 DeepMind paper on transformers to solve problems in parallel rather than sequentially, which led to the massive models that could be supported by cloud models. The 1000x growth in two years is unprecedented even from a tech perspective. Models have reached a level of scale where they can solve emergent challenges that they have not been trained on. This does not imply consciousness but does demonstrate the ability to analyze complex patterns and systems behavior. Amalgam Insights notes that this reflects a common trend in technology where new technology approaches often take a number of years to come to market, only to be treated as instant successes once they reach mainstream adoption.
The exponential growth of AI usage was accentuated in March 2023 when OpenAI, Microsoft, Google, and others provided an unending stream of AI-based announcements including OpenAI’s GPT 4 and GPT Plugins, Microsoft 365 Copilot and Microsoft Security Copilot, Google providing access to its generative AI Bard, Stanford’s $600 Alpaca generative AI model, and Databricks’ Dolly, which allows companies to build custom GPT-like experiences. This set of announcements, some of which were made during the Workday Innovation Summit, shows the immense nature of Workday’s opportunity as one of the premier enterprise data sources in the world that will both be integrated into all of these AI approaches.
Chakraborty points out that the weaknesses of GPT include bad results and a lack of explainability in machine learning, bad actors (including IP and security concerns), and the potential Environmental, Social, and Governance costs associated with financial, social, and environmental concerns. As with all technology, GPT and other generative AI models take up a lot of energy and resources without any awareness of how to throttle down in a sustainable and still functional manner. From a practical perspective, this means that current AI systems will be challenged to manage uptime as all of these new services attempt to benchmark and define their workloads and resource utilization. These problems are especially problematic in enterprise technology as the perceived reliability of enterprise software is often based on near-perfect accuracy of calculating traditional data and analytic outputs.
Amalgam Insights noted in our review of ChatGPT that factual accuracy and intellectual property attribution have been largely missing in recent AI technologies that have struggled to understand or contextualize a question based on surroundings or past queries. The likes of Google and Meta have focused on zero-shot learning for casual identification of trends and images rather than contextually specific object identification and topic governance aligned to specific skills and use cases. This is an area where both plug-ins and the work of enterprise software companies will be vital over the course of this year to augment the grammatically correct responses of generative AI with the facts and defined taxonomies used to conduct business.
Amalgam also found it interesting that Chakraborty mentioned that the future of models would include high-quality data and smaller models custom-built to industry and vertical use cases. This is an important statement because the primary discussion in current AI circles is often about how bigger is better and how models compete on having hundreds of billions of parameters to consider. In reality, we have reached the level of complexity where a well-trained model will provide responses that reflect the data that it has been trained on. The real work at this point is on how to better contextualize answers and how to separate quantitative and factual requests from textual and grammatical requests that may be in the same question. The challenge of accurate tone and grammar is very different from the ability to understand how to transform an eigenvector and get accurate quantitative output. Generative AI tends to be good at grammar but is challenged by quantitative and fact-based queries that may have answers that differ from its grammatical autocompletion logic.
Chakraborty pointed out that reinforcement learning has proven to be more useful than either supervised or unsupervised training for machine learning, as it allows models to look at user behavior rather than forcing direct user interaction. This Workday focus both provides efficacy of scale and takes advantage of Workday’s existing platform activities. This combination of reinforcement training and Workday’s ownership of its Skills Cloud will provide a sizable advantage over most of the enterprise AI world in aligning general outputs to the business world.
Amalgam Insights notes here that another challenge of the AI discussion is how to create an ‘unbiased’ approach for training and testing models when the more accurate question is to document the existing biases and assumptions that are being made. The sooner we can move from the goal of being “unbiased” to the goal of accurately documenting bias, the better we will be able to trust the AI we use.
Recommendations for the Amalgam Community on Where Workday is Headed Next
Obviously, this summit provided Amalgam Insights both with a lot of food for thought provided by Workday’s top executives. The introductory remarks summarized above were followed up with insight and guidance on Workday’s product roadmap across both the HR and finance categories where Workday has focused its product efforts, as well as visibility to the go-to-market and positioning, approaches that Workday plans to provide in 2023. Although much of these discussions were held under a non-disclosure agreement, Amalgam Insights will try to use this guidance to help companies to understand what is next from Workday and what customers should request. From an AI perspective, Amalgam Insights believes that customers should push Workday in the following areas based on Workday’s ability to deliver and provide business value.
- Use the data model to both create and support large language models (LLMs). The data model is a fundamental advantage in setting up machine learning and chat interfaces. Done correctly, this is a way to have a form of Ask Me Anything for the company based on key corporate data and the culture of the organization. This is an opportunity to use trusted data to provide relevant advice and guidance to the enterprise. As one of the largest and most trusted data sources in the enterprise software world, Workday has an opportunity to quickly build, train, and deploy models on behalf of customers, either directly or through partners. With this capability, “Ask Workday” may quickly become the HR and finance equivalent of “Ask Siri.”
- Use Workday’s Skills Cloud as a categorization to analyze the business, similar to cost center, profit center, geographic region, and other standard categories. Workforce optimization is not just about reducing TCO, but aligning skills, predicting succession and future success potential, and market availability for skills. Looking at the long-term value of attracting valuable skills and avoiding obsolete skills is an immense change for the Future of Work. Amalgam Insights believes that Workday’s market-leading Skills Cloud provides an opportunity for smart companies to analyze their company below the employee level and actually ascertain the resources and infrastructure associated with specific skills.
- Workday still has room to improve regarding consolidation, close, and treasury management capabilities. In light of the recent Silicon Valley Bank failure and the relatively shaky ground that regional and niche banks currently are on, it’s obvious that daily bank risk is now an issue to take into account as companies check if they can access cash and pay their bills. Finance departments want to consolidate their work into one area and augment a shared version of the truth with individualized assumptions. Workday has an opportunity to innovate in finance as comprehensive vendors in this space are often outdated or rigidly customized on a per-customer level that does not allow versions to scale out in a financially responsible way as the Intelligent Data Core allows. And Workday’s direct non-ERP planning competitors mostly lack Workday’s scale both in its customer base and consultant partner relationships to provide comprehensive financial risk visibility across macroeconomic, microeconomic, planning, budgeting, and forecasting capabilities. Expect Workday to continue working on making this integrated finance, accounting, and sourcing experience even more integrated over time and to pursue more proactive alerts and recommendations to support strategic decisions.
- Look for Workday Extend to be accessed more by technology vendors to create custom solutions. The current gallery of solutions is only a glimpse of the potential of Extend in establishing Workday-based custom apps. It only makes sense for Workday to be a platform for apps and services as it increasingly wins more enterprise data. From an AI perspective, Amalgam Insights would expect to see Workday Extend increasingly working with more plugins (including ChatGPT plugins), data models, and machine learning models to guide the context, data quality, hyperparameterization, and prompts needed for Workday to be an enterprise AI leader. Amalgam Insights also expects this will be a way for developers in the Workday ecosystem to take more advantage of the machine learning and analytics capabilities within Workday that are sometimes overlooked as companies seek to build models and gain insights into enterprise data.