Businesses face the challenge of managing a variety of workforce challenges across the wide variety of people at the company: freelancers, outsourcing firms, consultants, contingent labor, and full-time labor. The United States Government Accountability Office estimates that about 40% of workers are not full-time workers and fall within a variety of roles including contractors, part-time workers, and on-call workers that may track time through different systems and methods. With this challenge in mind, companies need a comprehensive management view that automates processes and helps companies focus on conducting work more quickly rather than be mired in a sea of paperwork and processes. Workforce management is no longer simply a matter of managing active full-time employees, but supporting a comprehensive practice that consolidates workforce management across contingent, part-time, full-time, and other categories of workers.
To effectively manage their hybrid workforce effectively across financial, operational, and management capacities, companies must consolidate workforce management tasks onto a single platform and a consistent set of data to avoid constant switching back and forth across inconsistent data. This platform should include contingent labor, internal labor, time and payroll, workforce scheduling, financial budgeting, employee engagement, and onboarding capabilities, including governance, risk, and compliance management across all areas. Data across all of these areas should ideally be within a single data store that provides a shared version of the truth for all stakeholders in workforce management across HR, finance, and line-of-business management roles.
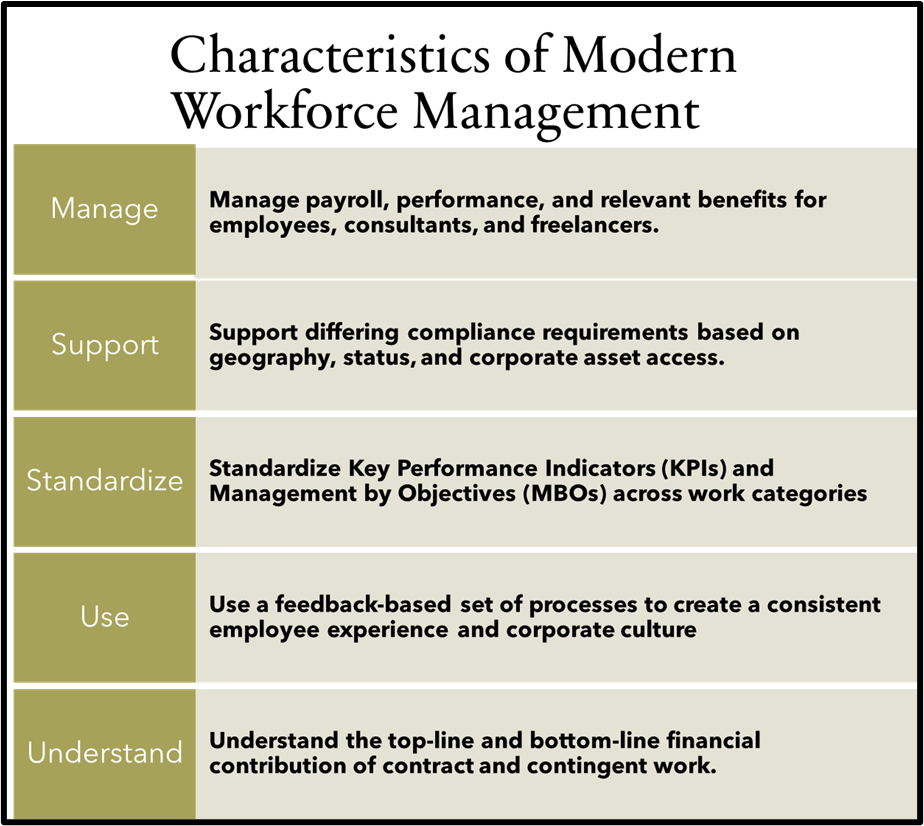
Amalgam Insights believes the following capabilities should be considered in developing a comprehensive workforce management system.
Manage payroll, performance, and relevant benefits for employees, consultants, and freelancers.
Workforce management efforts must consider the combination of standard payroll systems, time and attendance systems, scheduling systems, contingent labor management, on-demand services, third-party temporary labor and consulting firms, and self-employed contractors. In doing so, companies must decide which benefits and services are consistent across various labor types and what resources are needed to maximize the productivity of each class of workers. Regardless of labor type, compensation must be timely, accurate, and provided based on contractual agreements based on relevant labor law. By managing all classes of workers across a shared and consistent set of characteristics, companies may be better positioned to see if there are part-time or contingent workers who should be made full-time employees or to see which tasks are better supported by specific workers, skillsets, geographies, shifts, and other identifying work characteristics.
Supporting differing compliance requirements based on geography, status, and corporate asset access.
Workers with privileged access to trade secrets or classified information must all be treated with relevant compliance and confidentiality standards regardless of their work categorization. At the same time, companies must manage differing standards across wages, benefits, and tax obligations that exist in each jurisdiction where a worker is located.
Standardizing Key Performance Indicators (KPIs) and Management by Objectives (MBOs) across different work categories by focusing on the quality and quantity of relevant outputs and deliverables.
Even within a single department, the combination of roles, geographies, seniority, and employee status can lead to widely disparate individual goals. As companies identify appropriate KPIs and MBOs on an individual level that maximizes the value that each person brings to the workplace, they must also ensure that teams are aligned to shared corporate success metrics rather than disparate and disconnected metrics that may inadvertently pit workers against each other to pursue personal success.
Using a feedback-based set of processes to create a consistent employee experience and corporate culture that provides all workers with a shared set of expectations, goals, worker preferences, and employee support.
Employee feedback is only as useful as the corpus of data created and the management response associated with the suggestions and criticisms provided. At the same time, feedback can also be part of a continuous learning and continuous improvement initiative if feedback is stored as analytic and decision-guiding data that is tracked and monitored over time. Feedback can also be analyzed to see if workers are engaged in processes that are designed to improve the worker or corporate experience.
Understand the top-line and bottom-line financial contribution of contract and contingent work.
Although revenue per full-time employee is an outward-facing metric used by public companies to show efficiency, the business reality is that contractors and part-time employees also represent investments that should be reflected in workforce costs in determining corporate productivity and profitability. If companies are effectively replacing skills with contingent labor, this should be noted and tracked. Conversely, if there are significant gaps between full-time and other employees, companies should figure out the cause of these gaps and whether they can be closed through training, onboarding, or technical augmentation.
Taking Steps to Create a Consolidated Workforce Management Environment
Ultimately, companies have a responsibility to support the relevant stakeholders and shareholders associated with the company. However, this responsibility cannot be met if the company lacks consistent visibility to every worker who is attached to corporate work output, regardless of employment status, geography, department, or role. As companies seek to improve productivity and to allow executives to be more strategic in their approach to support productive workers while maintaining all relevant compliance responsibilities and a shared version of all relevant data, Amalgam Insights provides the following recommendations for human resources, finance, and managerial roles tasked with creating a better work environment.
First, ensure that you have the data necessary to maintain consistency of work expectations. Workers should be able to expect some baseline of employee experience even as they differ in location, employment status, and compensation if for no other reason than to provide every worker with a standard set of expectations and professional responsibilities.
Second, measure the profitability and revenue across the entire workforce based on a holistic view of hours, skills, geographies, and business goals. This capability can potentially uncover if specific hiring or labor sourcing strategies may be more profitable, or at least aligned to higher revenue, rather than simply treating all hiring and contracting exercises as an exercise in managing costs.
Finally, manage contingent labor with metrics and standards similar to traditional employee labor. When 40% of labor consists of either part-time, contractors, or on-demand workers, a workforce management solution that only looks at full-time payroll, onboarding, time, attendance, and benefits is no longer sufficient to understand the finance and operational details of the holistic workforce. Frontline and hourly workers seeking to manage their scheduling and time need a consistent and mobile experience on par with full-time workers. Regardless of how these metrics are presented from a public perspective, companies must have an internal basis for tracking the skills and work of every person who conducts work for a company, regardless of formal employment status.
By taking these steps, companies can fully empower all workers to acknowledge their contributions, manage skill portfolios, and further invest in the success of the complete workforce.
“The status quo is not a neutral state, but a mindset to uphold the decisions of the past.”
In 2023, effective business planning, budgeting, and forecasting is a necessary capability to keep organizations running. Already this year, we have seen unexpected banking failures, unpredictable labor markets, and continued supply chain and logistics challenges based on geopolitical challenges. In light of these challenges, Amalgam Insights believes that businesses must have a shared version of the truth that they use as they look at their budget and finances.
And, in this case, we specifically talk about a “shared” version of the truth rather than the “single version of the truth” typically associated with data warehouses and enterprise applications. This is because data changes quickly and every stakeholder can potentially make different decisions to define and augment their data, even basic changes such as language and currency translation that can lead to different versions of the truth. In this analytically enhanced and globally complicated world, it makes more sense to have a shared version of the truth that is augmented with personalized or localized data and assumptions. However, this consistently shared version of the truth can be hard to accomplish in organizations where planning is handled in a distributed and personalized manner through spreadsheets. In the enterprise world, finance professionals are inured to the basic realities of auditable data, processes, and results. And they are often asked to provide reports and memos that are used at the executive level or by external investors and public markets to ascertain the health of the market. Given the assumed importance of this formality, why would experienced professionals use spreadsheets in the first place?
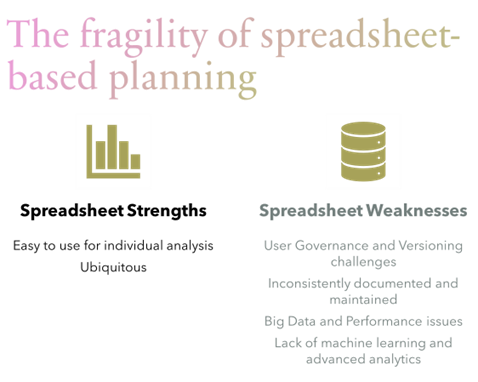
Let’s face it; spreadsheets are easy to use. They are the lingua franca of data; a format that every experienced data user has been trained on. And with plug-ins and Visual Basic, spreadsheets can now handle relatively complex analytic use cases. Even if they aren’t quite data science tools, spreadsheets can provide structured analytic outputs. Also, spreadsheets are accessible on every computer through Excel, Google Sheets, or other common spreadsheet software. And with the emergence of cloud-based spreadsheets, it is now possible for two or more people to collaborate within a single spreadsheet.
Spreadsheets also provide users with the ability to customize their own analytic views with their own personalized views of data and the ability to hypothesize by building their own models. Who hasn’t looked at data and wondered “what if the data looked a bit differently?” or “what if we have a drastic scenario that suddenly increases or decreases a fundamental aspect of the business?” In light of COVID, rapid interest rate hikes, global shortages in commodities production, trained labor shortages, and the increasingly unstable banking environment we are in, it is important to be able to test potential extreme assumptions and support a wide variety of scenarios. Between the ease of use, availability, and personalization aspects of spreadsheets, it is not hard to figure out why spreadsheets are still a leading tool for financial planning and analysis. Even so, Amalgam Insights has found that once organizations pass Dunbar’s number (approximately 150 employees), they start to struggle with collaborative tasks simply because it becomes difficult for any one employee to know all of the other employees who need to be involved in the business planning process and spreadsheets have been designed to maximize individual productivity, rather than collaborative work, for decades. From a practical perspective, people tend to work with the people they know best. This is fine for a small company with a dedicated office where everyone knows each other. According to US Census data, the typical 1,000-person company has 19 locations, making it highly unlikely that all of the key budget stakeholders will be in one office. In this regard, Amalgam Insights finds the following challenges in supporting spreadsheet-based planning at scale.
The distributed nature of work also makes spreadsheet governance a challenge, as it is easy for spreadsheets to suffer from version control issues, a structured workflow process, and for file owners to lose control of the inputs and outputs that they are responsible for supporting. The lack of version control, workflow, and activity tracking is especially challenging in industries and geographies that require tracking of any personal data either related to employees or customers.
Spreadsheets also struggle in large data environments, which are quickly becoming commonplace in the business planning world. Although a core enterprise database may only be a few gigabytes, accurate planning now often includes access to sales, operations, and potentially even IT transactional data sources that can quickly expand beyond the memory and data size constraints that spreadsheets are designed to use. From Amalgam Insights’ perspective, the size and variety of data are the biggest technical constraints that spreadsheets face as planning solutions.
Spreadsheets lack advanced analytic and machine learning capabilities. Although algorithmic, statistical, and machine learning tools are increasingly becoming part of the FP&A world, especially in forecasting, Amalgam Insights finds in practice that most organizations have not yet embraced complex analytics as a core part of their FP&A approach. Based on current job site metrics, Amalgam Insights estimates that less than 2% of FP&A professionals currently have a machine learning or data science certification or degree, making this an early innovator capability that has still not crossed the chasm to become a standard job requirement for FP&A.
But perhaps the most significant challenge with spreadsheet models is that they are often fragile: created based on the logic of a single person rather than on defined business logic and with little to no documentation associated with the plans, forecasting algorithms, and multi-tabular complexity that inevitably occurs when a spreadsheet is the primary planning tool for a business, which can also lead to costly data accuracy issues. The model is only as adaptable as the spreadsheet creator’s knowledge of the industry and is dependent on that employee staying employed. Considering that it is unrealistic to expect an FP&A senior analyst to remain in that role for more than five years before either getting promoted or getting a better offer, this human risk is a significant challenge for business planning solutions.
As organizations grow in size to support more than a handful of locations and a set of workers that exceeds Dunbar’s number of 150 colleagues, Amalgam Insights believes that it becomes necessary to adopt a formalized planning solution that supports collaboration, scale, advanced analytics, continuous planning across many scenarios, and advanced forecasting analytics. Otherwise, it is difficult for businesses to maintain a consistent and shared version of the truth across financial planning and analysis personnel that can drive both departmental and executive planning efforts.
Ultimately, the use of spreadsheets as a formal system of record for business planning is a risky one for any organization with a formal corporate structure, governed industry or geography, or any organization that has a significantly distributed business. The ubiquity of the spreadsheet makes it an easy place to start modeling a budget, and the value of the spreadsheet in helping users to structure small datasets will exist for the foreseeable future. But the fragility of the data structure, lack of user and version control governance, inability to scale, and the difficulty of verifying data with other sources while avoiding human error all lead to the need of supporting a more formalized planning solution over time. As organizations face a future of keeping distributed groups focused on a shared version of the truth and collectively consider a variety of scenarios at any given time, the risk of spreadsheet fragility needs to be matched up against the value of using a formalized FP&A solution designed to analyze, govern, and protect all relevant business data, formulas, and outcomes.
Analytics in the Retail and Consumer Packaged Goods (CPG) markets is more complex than the average corporate data ecosystem because of the variety of analytic approaches needed to support these organizations. Every business has operational management capabilities for core human resources and financial management, but retail adds the complexities of hybrid workforce management, scheduling, and operational analytics as well as the front-end data associated with consumer marketing, e-commerce, and transactional behavior across every channel.
In contrast, when retail organizations look at middle-office and front-office analytics, they are trying to support a variety of timeframes ranging from intraday decisions associated with staffing and customer foot traffic to the year-long cycles that may be necessary to fulfill large wholesale orders for highly coveted goods in the consumer market. Over the past three years, operational consistency has become especially challenging to achieve as COVID, labor skill gaps, logistical bottlenecks, commodity shortages, and geopolitical battles have all made supply chain a massive dynamic risk factor that must be consistently monitored across both macro and microeconomic business aspects.
The lack of alignment and connection between the front office, middle-office, and administrative analytic outputs can potentially lead to three separate silos of activity in the retail world— connected only by some basic metrics, such as receipts and inventory turnover, that are interpreted in three different ways. Like the parable of the blind men and an elephant where each person feels one part of the elephant and imagines a different creature, the disparate parts of retail organizations must figure out how to come together, as the average net margin for general retail companies is about 2% and that margin only gets lower for groceries and for online stores.
Analytic opportunities to increase business value exist across the balance sheet and income statement. Even though consumer sentiment, foot traffic, and online behavior are still key drivers for retail success, analytic and data-driven guidance can provide value across infrastructure, risk, and real-time operations. Amalgam Insights suggests that each of these areas requires a core analytic focus that is different and reflects the nature of the data, the decisions being made, and the stakeholders involved.
Facing Core Retail Business Challenges
First, retail and CPG organizations face core infrastructure, logistics, and data management challenges that typically require building out historic analysis and quantitative visibility capabilities often associated with what is called descriptive or historical analytics. When looking at infrastructure factors such as real estate, warehousing, and order fulfillment issues, organizations must have access to past trends, costs, transactions, and the breadth of relevant variables that go into real estate costs or complex order fulfillment associated with tracking perfect order index.
This pool of data ideally combines public data, industry data, and operational business data that includes, but is not limited to, sales trends, receipts, purchase orders, employee data, loyalty information, customer information, coupon redemption, and other relevant transactional data. This set of data needs to be available as analytic and queryable data that is accessible to all relevant stakeholders to provide business value. In practice, this accessibility typically requires some infrastructure investment either by a company or a technology vendor willing to bear the cost of maintaining a governed and industry-compliant analytic data store. By doing so, retail organizations have the opportunity to improve personalization and promotional optimization.
A second challenge that retail analytics can help with is associated with the risk and compliance issues that retail and CPG organizations face, including organized theft, supplier risk, and balancing risk and reward tradeoffs. A 2022 National Retail Federation (NRF) survey showed that organized retail crime had increased over 26% year over year, driving the need to identify and counter organized theft efforts and tactics more quickly. Retailer risk for specific goods and brands also needs to be quantified to identify potential delays and challenges or to determine whether direct store delivery and other direct-to-market tactics may end up being a profitable approach for key SKUs. Risk also matters from a profitability analysis perspective as retail organizations seek to make tradeoffs between the low-margin nature of retail business and the consumer demand for availability, personalization, automation, brand expansion, and alternative channel delivery that may provide exponential benefits to profits. From a practical perspective, this risk analysis requires investment in a combination of predictive analytics and the ability to translate the variance and marginal cost associated with new investments with projected returns.
A third challenge for retail analytics is to support real-time operational decisions. This use case requires access to streaming and log data associated with massive volumes of rapid transactions, frequently updated time-series data, and contextualized scenarios based on multi-data-sourced outcomes. From a retail outcome perspective, the practical challenge is to make near-real-time decisions, such as same-day or in-shift decisions to support stocking, scheduling, product orders, pricing and discounting decisions, placement decisions, and promotion. In addition, these decisions must be made in the context of broader strategic and operational concerns, such as brand promise, environmental concerns, social issues, and regulatory governance and compliance associated with environmental, social, and governance (ESG) concerns.
As an example, supply chain shortages often come from unexpected sources. An unexpected geopolitical example occurred in the United States when the government’s use of containers as a temporary barrier to block illegal immigration checkpoints on the US-Mexico border led to shortages at US ports for delivery. This delay in accessing containers was not predictable based solely on standard retail metrics and behavior and demonstrates one example of how unexpected political issues can affect a hyperconnected logistical supply chain.
Recommendations for Upgrading Retail Analytics in the 2020s
To solve these analytic problems, retail and CPG organizations need to allow line-of-business, logistics, and sourcing managers to act quickly with self-service and on-demand insights based on all relevant data. This ultimately means that to take an analytic approach to retail, Amalgam Insights recommends the following three best practices in creating a more data-driven business environment.
Create and implement an integrated finance, operational, and workforce management environment. Finance, inventory, and labor must be managed together in an integrated business data store and business planning environment or the retail organization falls apart. Whether companies choose to do this by knitting together multiple applications with data management and integration tools or by choosing a single best-in-breed suite, retail businesses have too many moving parts to split up core operational data across a variety of functional silos and business roles that do not work together. In the 2020s, this is a massive operational disadvantage.
Adopt prescriptive analytics, decision intelligence, and machine learning capabilities above and beyond basic dashboards. When retail organizations look at analytics and data outputs, it is not enough to gain historical visibility. In today’s AI-enabled world, companies must have predictive analytics, statistical analysis, detect anomalies quickly, and have the ability to translate business data into machine learning and language models for the next generation of analytics and decision intelligence. Retail can be more proactive and prescriptive with AI and ML models trained to their enterprise data to support more personalized and contextualized purchasing experiences.
Implement real-time alerts with relevant and actionable retail information. Finally, timely and contextual alerts are also now part of the analytic process. As retail organizations have moved from seasonal purchases and monthly budgeting to daily or even hourly decisions, regional and branch managers need to be able to move quickly if there are signs of business danger coordinated revenue leakage, brand damage across any of the products held within the store, unexpected weather phenomena, labor issues, or other incipient macro or microeconomic threats.
We are in a time of transformational change as the awareness of artificial intelligence (AI) grows during a time of global uncertainty. The labor supply chain is fluctuating quickly and the economy is on rocky ground as interest rates and geopolitical strife create currency challenges. Meanwhile, the commodity supply chain is in turmoil, leading to chaos and confusion. Rising interest rates and a higher cost of money are only adding to the challenges faced by those in the global business arena. In this world where technology is dominant in the business world, the global economic foundation is shifting, and the worlds of finance and talent are up for grabs, Workday stepped up to hold its AI and ML Innovation summit to show a way forward for the customers of its software platform, including a majority of the Fortune 500 that use Workday already as a system of record.
The timing of this summit will be remembered as a time of rapid AI change, with new major announcements happening daily. OpenAI’s near-daily announcements regarding working with Microsoft, launching ChatGPT, supporting plug-ins, and asking for guidance on AI governance are transforming the general public’s perception of AI. Google and Meta are racing to translate their many years of research in AI into products. Generative AI startups already focused on legal, contract, decision intelligence, and revenue intelligence use cases are happy to ride the coattails of this hype. Universities are showing how to build large language models such as Stanford’s Alpaca. And existing machine learning and AI companies such as Databricks are showing how to build custom models based on existing data for a fraction of the cost needed to build GPT.
In the midst of this AI maelstrom, Workday decided to chase the eye of the hurricane and put stakes in the ground on its current approach to innovation, AI, and ML. From our perspective, we were interested both in the executive perspective and in the product innovation associated with this Brave New World of AI.
Enter the Co-CEO – Carl Eschenbach
Workday’s AI and ML Innovation Summit commenced with an introduction of the partners and customers that would be present at the event. The Summit began with a conversation between Workday’s Co-CEOs, Aneel Bhusri and Carl Eschenbach, where Eschenbach talked about his focus on innovation and growth for the company. Eschenbach is not new to Workday, having been on its board during his time at Sequoia Capital, where he also led investments in Zoom, UIPath, and Snowflake. Having seen his work at VMware, Amalgam Insights was interested to see Eschenbach take this role and help Workday evolve its growth strategy from an executive level. From the start, both Bhusri and Eschenbach made it clear that this Co-CEO team is intended to be a temporary status with Eschenbach taking the reins in 2024, while Bhusri becomes the Executive Chair of Workday.
Eschenbach emphasized in this session that Workday has significant opportunities in providing a full platform solution, and its international reach requires additional investment both in technology and go-to-market efforts. Workday partners are essential to the company’s success and Eschenbach pointed out a recent partnership with Amazon to provide Workday as a private offering that can use Amazon Web Service contract dollars to purchase Workday products once the work is scoped by Workday. Workday executives also mentioned the need for consolidation, which is one of Amalgam Insights’ top themes and predictions for enterprise software for 2023. The trend in tech is shifting toward best-in-suite and strategic partnering opportunities rather than a scattered best-in-breed approach that may sprawl across tens or even hundreds of vendors.
These Co-CEOs also explored what Workday was going to become over the next three to five years to take the next stage of its development after Bhusri evolved Workday from an HR platform to a broader enterprise software platform. Bhusri sees Workday as a system of record that uses AI to serve customer pain points. He poses that ERP is an outdated term, but that Workday is currently categorized as a “services ERP” platform in practice when Workday is positioned as a traditional software vendor. Eschenbach adds that Workday is a management platform across people and finances on a common multi-tenant platform.
From Amalgam Insights’ perspective, this is an important positioning as Workday is establishing that its focus is on two of the highest value and highest cost issues in the company: skills and money. Both must exist in sufficient quantities and quality for companies to survive.
The Future of AI and Where Workday Fits
We then heard from Co-President Sayan Chakraborty, who took the stage to discuss the “Future of Work” across machine learning and generative AI. As a member of the National Artificial Intelligence Advisory Committee, the analysts in the audience expected Chakraborty to have a strong mastery of the issues and challenges Workday faced in AI and this expectation was clarified by the ensuing discussion.
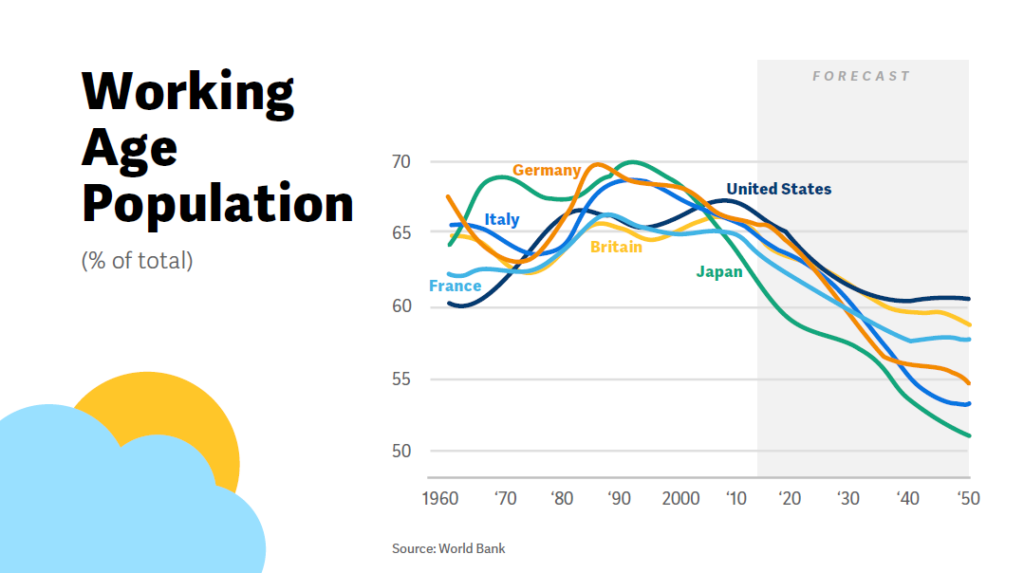
Chakraborty started by saying that Workday is monomaniacally focused on machine learning to accelerate work and points out that we face a cyclical change in the nature of the working age across the entire developed world. As we deal with a decline in the percentage of “working-age” adults on a global scale, machine learning exists as a starting point to support structural challenges in labor structures and work efforts.
To enable these efforts, Chakraborty brought up the technology, data, and application platforms based on a shared object model, starting with the Workday Cloud Platform and including analytics, Workday experience, and machine learning as specific platform capabilities. Chakraborty referenced the need for daily liquidity FDIC requests as a capability that is now being asked for in light of banking failures and stresses such as the recent Silicon Valley Bank failure.
Workday has four areas of differentiation in machine learning: data management, autoML (automated machine learning, including feature abstraction), federated learning, as well as a platform approach. Workday’s advantage in data is stated across quantity, quality associated with a single data model, structure and tenancy, and the amplification of third-party data. As a starting point, this approach allows Workday to support models based on regional or customer-specific data supported by transfer learning. At this point, Chakraborty was asked why Workday has Prism in a world of Snowflake and other analytic solutions capable of scrutinizing data and supporting analytic queries and data enrichment. Prism is currently positioned as an in-platform capability that allows Workday to enrich its data, which is a vital capability as companies face the battle for context across data and analytic outputs.
Amalgam Insights will dig into this in greater detail in our recommendations and suggestions, but at this point we’ll note that this set of characteristics is fairly uncommon at the global software platform level and presents opportunities to execute based on recent AI announcements that Workday’s competitors will struggle to execute on.
Workday currently supports federated machine learning at scale out to the edge of Workday’s network, which is part of Workday’s differentiation in providing its own cloud. This ability to push the model out to the edge is increasingly important for supporting geographically specific governance and compliance needs (dubbed by some as the “Splinternet“) as Workday has seen increased demand for supporting regional governance requests leading to separate US and European Union machine learning training teams each working on regionally created data sources.
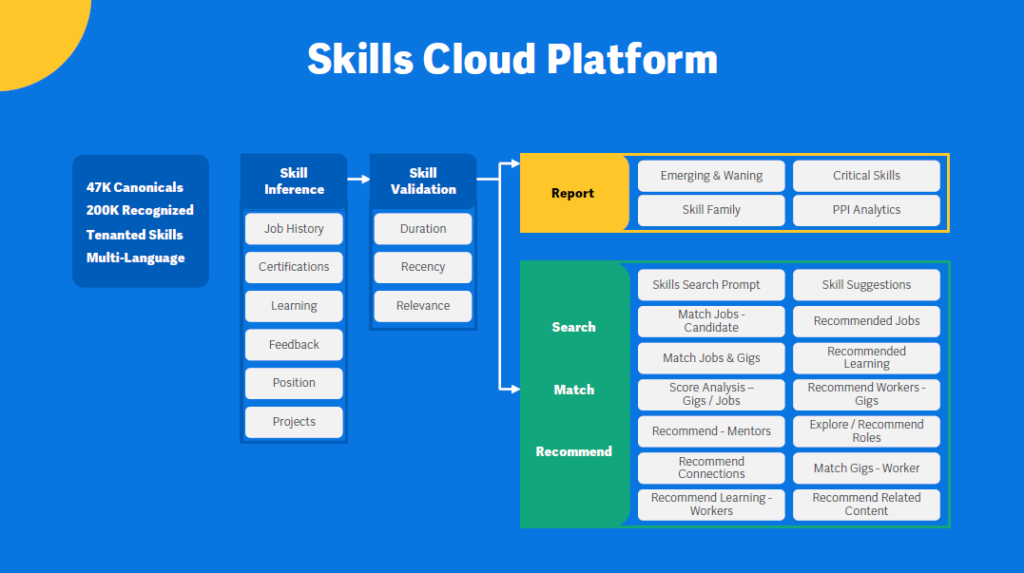
Chakraborty compared Workday’s approach of a platform machine learning approach leading to a variety of features to traditional machine learning feature-building approaches where each feature is built through a separate data generation process. The canonical Workday example is Workday’s Skills Cloud platform where Workday currently has close to 50,000 canonical skills and 200,000 recognized skills and synonyms scored for skill strength and validity. This Skills Cloud is a foundational differentiator for Workday and one that Amalgam Insights references regularly as an example of a differentiated syntactic and semantic layer of metadata that can provide differentiated context to a business trying to understand why and how data is used.
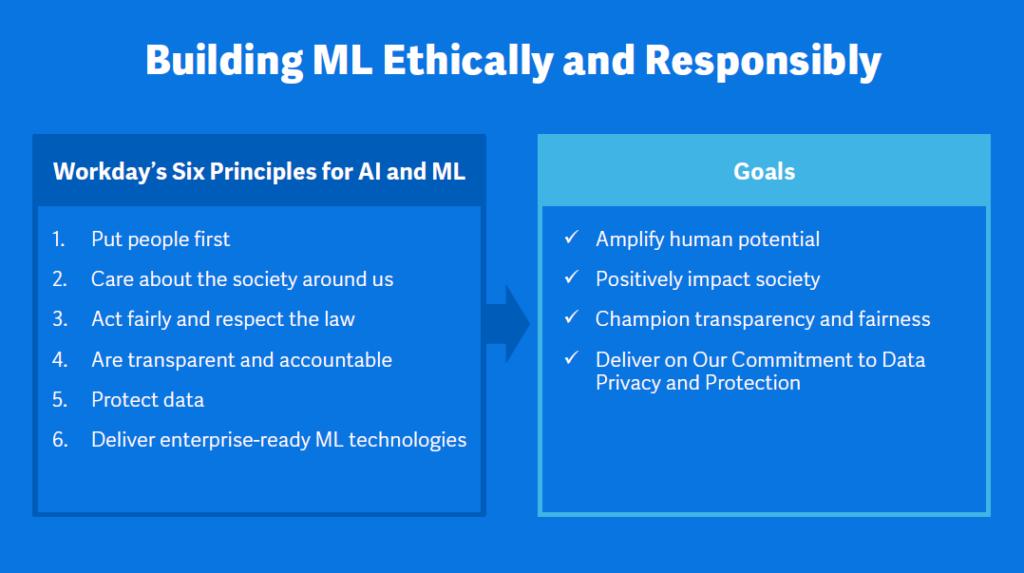
Workday mentioned six core principles for AI and ML, including people and customers, built to ensure that the machine learning capabilities developed are done through ethical approaches. In this context, Chakraborty also mentioned generative AI and large language models, which are starting to provide human-like outputs across voice, art, and text. He points out how the biggest change in AI occurred in 2006 when NVIDIA created GPUs, which used matrix math to support the constant re-creation of images. Once GPUs were used from a computational perspective, they made massively large parameter models possible. Chakraborty also pointed out the 2017 DeepMind paper on transformers to solve problems in parallel rather than sequentially, which led to the massive models that could be supported by cloud models. The 1000x growth in two years is unprecedented even from a tech perspective. Models have reached a level of scale where they can solve emergent challenges that they have not been trained on. This does not imply consciousness but does demonstrate the ability to analyze complex patterns and systems behavior. Amalgam Insights notes that this reflects a common trend in technology where new technology approaches often take a number of years to come to market, only to be treated as instant successes once they reach mainstream adoption.
Chakraborty points out that the weaknesses of GPT include bad results and a lack of explainability in machine learning, bad actors (including IP and security concerns), and the potential Environmental, Social, and Governance costs associated with financial, social, and environmental concerns. As with all technology, GPT and other generative AI models take up a lot of energy and resources without any awareness of how to throttle down in a sustainable and still functional manner. From a practical perspective, this means that current AI systems will be challenged to manage uptime as all of these new services attempt to benchmark and define their workloads and resource utilization. These problems are especially problematic in enterprise technology as the perceived reliability of enterprise software is often based on near-perfect accuracy of calculating traditional data and analytic outputs.
Amalgam Insights noted in our review of ChatGPT that factual accuracy and intellectual property attribution have been largely missing in recent AI technologies that have struggled to understand or contextualize a question based on surroundings or past queries. The likes of Google and Meta have focused on zero-shot learning for casual identification of trends and images rather than contextually specific object identification and topic governance aligned to specific skills and use cases. This is an area where both plug-ins and the work of enterprise software companies will be vital over the course of this year to augment the grammatically correct responses of generative AI with the facts and defined taxonomies used to conduct business.
Amalgam also found it interesting that Chakraborty mentioned that the future of models would include high-quality data and smaller models custom-built to industry and vertical use cases. This is an important statement because the primary discussion in current AI circles is often about how bigger is better and how models compete on having hundreds of billions of parameters to consider. In reality, we have reached the level of complexity where a well-trained model will provide responses that reflect the data that it has been trained on. The real work at this point is on how to better contextualize answers and how to separate quantitative and factual requests from textual and grammatical requests that may be in the same question. The challenge of accurate tone and grammar is very different from the ability to understand how to transform an eigenvector and get accurate quantitative output. Generative AI tends to be good at grammar but is challenged by quantitative and fact-based queries that may have answers that differ from its grammatical autocompletion logic.
Chakraborty pointed out that reinforcement learning has proven to be more useful than either supervised or unsupervised training for machine learning, as it allows models to look at user behavior rather than forcing direct user interaction. This Workday focus both provides efficacy of scale and takes advantage of Workday’s existing platform activities. This combination of reinforcement training and Workday’s ownership of its Skills Cloud will provide a sizable advantage over most of the enterprise AI world in aligning general outputs to the business world.
Amalgam Insights notes here that another challenge of the AI discussion is how to create an ‘unbiased’ approach for training and testing models when the more accurate question is to document the existing biases and assumptions that are being made. The sooner we can move from the goal of being “unbiased” to the goal of accurately documenting bias, the better we will be able to trust the AI we use.
Recommendations for the Amalgam Community on Where Workday is Headed Next
Obviously, this summit provided Amalgam Insights both with a lot of food for thought provided by Workday’s top executives. The introductory remarks summarized above were followed up with insight and guidance on Workday’s product roadmap across both the HR and finance categories where Workday has focused its product efforts, as well as visibility to the go-to-market and positioning, approaches that Workday plans to provide in 2023. Although much of these discussions were held under a non-disclosure agreement, Amalgam Insights will try to use this guidance to help companies to understand what is next from Workday and what customers should request. From an AI perspective, Amalgam Insights believes that customers should push Workday in the following areas based on Workday’s ability to deliver and provide business value.
Use the data model to both create and support large language models (LLMs). The data model is a fundamental advantage in setting up machine learning and chat interfaces. Done correctly, this is a way to have a form of Ask Me Anything for the company based on key corporate data and the culture of the organization. This is an opportunity to use trusted data to provide relevant advice and guidance to the enterprise. As one of the largest and most trusted data sources in the enterprise software world, Workday has an opportunity to quickly build, train, and deploy models on behalf of customers, either directly or through partners. With this capability, “Ask Workday” may quickly become the HR and finance equivalent of “Ask Siri.”
Use Workday’s Skills Cloud as a categorization to analyze the business, similar to cost center, profit center, geographic region, and other standard categories. Workforce optimization is not just about reducing TCO, but aligning skills, predicting succession and future success potential, and market availability for skills. Looking at the long-term value of attracting valuable skills and avoiding obsolete skills is an immense change for the Future of Work. Amalgam Insights believes that Workday’s market-leading Skills Cloud provides an opportunity for smart companies to analyze their company below the employee level and actually ascertain the resources and infrastructure associated with specific skills.
Workday still has room to improve regarding consolidation, close, and treasury management capabilities. In light of the recent Silicon Valley Bank failure and the relatively shaky ground that regional and niche banks currently are on, it’s obvious that daily bank risk is now an issue to take into account as companies check if they can access cash and pay their bills. Finance departments want to consolidate their work into one area and augment a shared version of the truth with individualized assumptions. Workday has an opportunity to innovate in finance as comprehensive vendors in this space are often outdated or rigidly customized on a per-customer level that does not allow versions to scale out in a financially responsible way as the Intelligent Data Core allows. And Workday’s direct non-ERP planning competitors mostly lack Workday’s scale both in its customer base and consultant partner relationships to provide comprehensive financial risk visibility across macroeconomic, microeconomic, planning, budgeting, and forecasting capabilities. Expect Workday to continue working on making this integrated finance, accounting, and sourcing experience even more integrated over time and to pursue more proactive alerts and recommendations to support strategic decisions.
Look for Workday Extend to be accessed more by technology vendors to create custom solutions. The current gallery of solutions is only a glimpse of the potential of Extend in establishing Workday-based custom apps. It only makes sense for Workday to be a platform for apps and services as it increasingly wins more enterprise data. From an AI perspective, Amalgam Insights would expect to see Workday Extend increasingly working with more plugins (including ChatGPT plugins), data models, and machine learning models to guide the context, data quality, hyperparameterization, and prompts needed for Workday to be an enterprise AI leader. Amalgam Insights also expects this will be a way for developers in the Workday ecosystem to take more advantage of the machine learning and analytics capabilities within Workday that are sometimes overlooked as companies seek to build models and gain insights into enterprise data.
2023 is going to be a tough year for anybody managing technology. As we face the repercussions of inflation and high interest rates and the bubble of tech starts to be burst, we are seeing a combination of hiring freezes, increased focus on core business activities and the hoary request to “do more with less.”
Behind the cliche of doing more with less is the need to actually become more efficient with tech usage. This means adopting a FinOps (Financial Operations) strategy to cloud to go with your existing Telecom FinOps (aka Telecom expense) and SaaS FinOps (aka SaaS Management) strategies. And it means being prepared for new spend category challenges as companies will need to invest in technology to get work done at a time when it is harder to hire the right person at the right time. Here is a quick preview of our predictions.
14 Key Predictions for the IT Executive in 2023
To get the details on each of these trends and predictions and understand why they matter in 2023, download this report at no cost by filling out this quick form to join our low-volume bi-monthly mailing list. (Note: If you do not wish to join our mailing list, you can alsopurchase a personal license for this report.)
2022 was a banner year for artificial intelligence technologies that reached the mainstream. After years of being frustrated with the likes of Alexa, Cortana, and Siri and the inability to understand the value of machine learning other than as a vague backend technology for the likes of Facebook and Google, 2022 brought us AI-based tools that was understandable at a consumer level. From our perspective, the most meaningful of these were two products created by OpenAI: DALL-E and ChatGPT, which expanded the concept of consumer AI from a simple search or networking capability to a more comprehensive and creative approach for translating sentiments and thoughts into outputs.
DALL-E (and its successor DALL-E 2) is a system that can create visual images based on text descriptions. The models behind DALL-E look at relationships between existing images and the text metadata that has been used to describe those images. Based on these titles and descriptions, DALL-E uses diffusion models to start with random pixels that lead to generated images based on these descriptions. This area of research is by no means unique to OpenAI, but it is novel to open up a creative tool such as DALL-E to the public. Although the outputs are often both interesting and surprisingly different from what one might have imagined, they are not without their issues. For instance, the discussion around the legal ownership of DALL-E created graphics is not clear, since Open AI claims to own the images used, but the images themselves are often based on other copyrighted images. One can imagine that, over time, an artistic sampling model may start to appear similar to the music industry where licensing contracts are used to manage the usage of copyrighted material. But this will require greater visibility regarding the lineage of AI-based content creation and the data used to support graphic diffusion. Until this significant legal question is solved, Amalgam Insights believes that the commercial usage of DALL-E will be challenging to manage. This is somewhat reminiscent of the challenges that Napster faced at the end of the 20th century as a technology that both transformed the music industry and had to deal with the challenges of a new digital frontier.
But the technology that has taken over the zeitgeist of technology users is ChatGPT and related use cases associated with the GPT (Generative Pre-Trained Transformer) autoregressive language model trained on 500 billion words across the web, Wikipedia, and books. And it has become the favorite plaything of many a technologist. What makes ChatGPT attractive is its ability to take requests from users asking questions with some level of subject matter specificity or formatting and to create responses in real-time. Here are a couple of examples from both a subject matter and creative perspective.
Example 1: Please provide a blueprint for bootstrapping a software startup.
This is a bit generic and lacks some important details on how to find funding or sell the product, but it is in line with what one might expect to see in a standard web article regarding how to build a software product. The ending of this answer shows how the autogenerative text is likely referring to prior web-based content built for search engine optimization and seeking to provide a polite conclusion based on junior high school lessons in writing the standard five-paragraph essay rather than a meaningful conclusion that provides insight. In short, it is basically a status quo average article with helpful information that should not be overlooked, but is not either comprehensive or particularly insightful for anyone who has ever actually started a business.
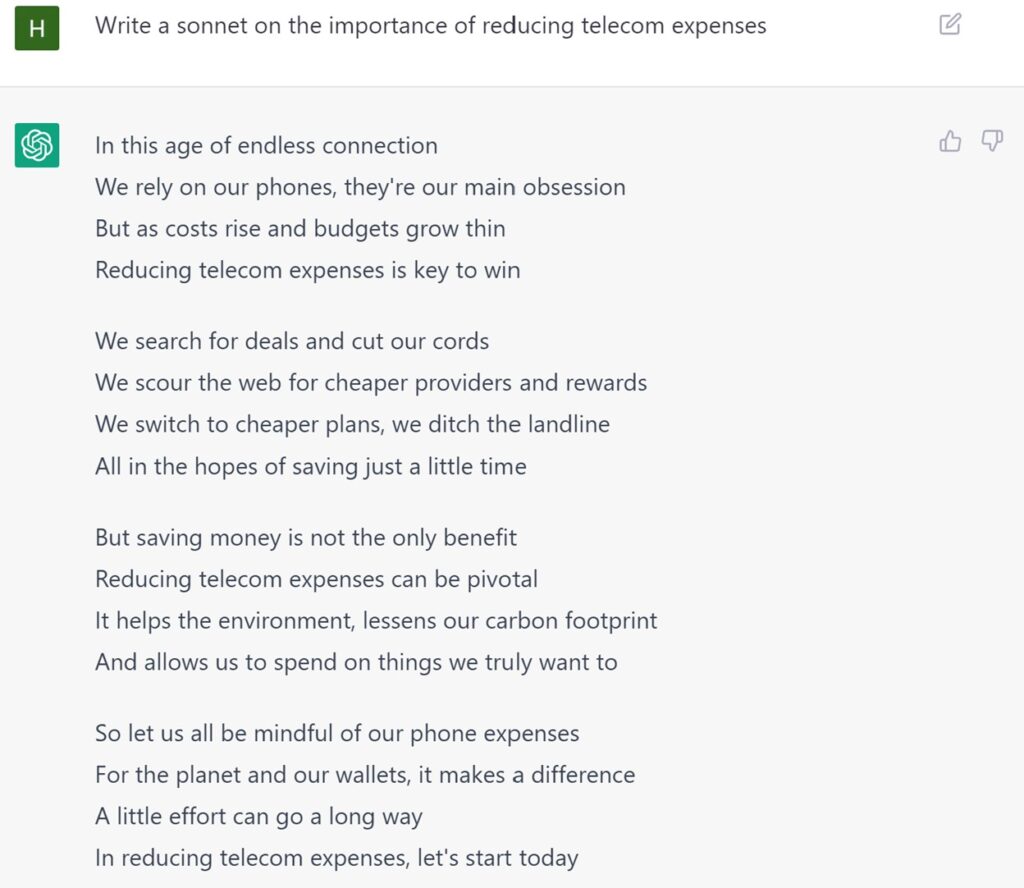
A second example of ChatGPT is in providing creative structural formats for relatively obscure topics. As you know, I’m an expert in technology expense management with over two decades of experience and one of the big issues I see is, of course, the lack of poetry associated with this amazing topic. So, again, let’s go to ChatGPT.
Example 2: Write a sonnet on the importance of reducing telecom expenses
As a poem, this is pretty good for something written in two seconds. But it’s not a sonnet, as sonnets are 14 lines, written in iambic pentameter (10 syllable lines split int 5 iambs, or a unstressed syllable followed by a stressed syllable) and split into three sections of four lines followed by a two-line section with a rhyme scheme of ABAB, CDCD, EFEF, GG. So, there’s a lot missing there.
So, based on these examples, how should ChatGPT be used? First, let’s look at what this content reflects. The content here represents the average web and text content that is associated with the topic. With 500 billion words in the GPT-3 corpus, there is a lot of context to show what should come next for a wide variety of topics. Initial concerns of GPT-3 have started with the challenges of answering questions for extremely specific topics that are outside of its training data. But let’s consider a topic I worked on in some detail back in my college days while using appropriate academic language in asking a version of Gayatri Spivak’s famous (in academic circles) question “Can the subaltern speak?”
Example 3: Is the subaltern allowed to fully articulate a semiotic voice?
Considering that the language and topic here is fairly specialized, the introductory assumptions are descriptive but not incisive. The answer struggles with the “semiotic voice” aspect of the question in discussing the ability and agency to use symbols from a cultural and societal perspective. Again, the text provides a feeling of context that is necessary, but not sufficient, to answer the question. The focus here is on providing a short summary that provides an introduction to the issue before taking the easy way out telling us what is “important to recognize” without really taking a stand. And, again, the conclusion sounds like something out of an antiseptic human resources manual in asking for the reader to consider “different experiences and abilities” rather than the actual question regarding the ability to use symbols, signs, and assumptions. This is probably enough of an analysis at a superficial level as the goal here isn’t to deeply explore postmodern semiotic theory but to test ChatGPT’s response in a specialized topic.
Based on these three examples, one should be careful in counting on ChatGPT to provide a comprehensive or definitive answer to a question. Realistically, we can expect ChatGPT will provide representative content for a topic based on what is on the web. The completeness and accuracy of a ChatGPT topic is going to be dependent on how often the topic has been covered online. The more complete an answer is, the more likely it is that this topic has already been covered in detail.
ChatGPT will provide a starting point for a topic and typically provide information that should be included to introduce the topic. Interestingly, this means that ChatGPT is significantly influenced by the preferences that have built online web text over the past decade of content explosion. The quality of ChatGPT outputs seems to be most impressive to those who treat writing as a factual exercise or content creation channel while those who look at writing as a channel to explore ideas may find it lacking for now based on its generalized model.
From a topical perspective, ChatGPT will probably have some basic context for whatever text is used in a query. It would be interesting to see the GPT-3 model augmented with specific subject matter texts that could prioritize up-to-date research, coding, policy, financial analysis, or other timely new content either as a product or training capability.
In addition, don’t expect ChatGPT to provide strong recommendations or guidance. The auto-completion that ChatGPT does is designed to show how everyone else has followed up on this topic. And, in general, people do not tend to take strong stances on web-based content or introductory articles.
Fundamentally, ChatGPT will do two things. First, it will make mediocre content ubiquitous. There is no need to hire people to write an “average” post for your website anymore as ChatGPT and other technologies either designed to compete with or augment it will be able to do this easily. If your skillset is to write grammatically sound articles with little to no subject matter experience or practical guidance, that skill is now obsolete as status quo and often-repeated content can now be created on command. This also means that there is a huge opportunity to combine ChatGPT with common queries and use cases to create new content on demand. However, in doing so, users will have to be very careful not to plagiarize content unknowingly. This is an area where, just like with DALL-E, OpenAI will have to work on figuring out data lineage, trademark and copyright infringement, and appropriation of credit to support commercial use cases. ChatGPT struggles with what are called “hallucinations” where ChatGPT makes up facts or sources because those words are physically close to the topic discussed in the various websites and books that ChatGPT uses. ChatGPT is a text generation tool that picks words based on how frequently they show up with other words. Sometimes that result will be extremely detailed and current and other times, it will look very generic and mix up related topics that are often discussed together.
Second, this tool now provides a much stronger starting point for writers seeking to say something new or different. If your point of view is something that ChatGPT can provide in two seconds, it is neither interesting or new. To stand out, you need to provide greater insight, better perspective, or stronger directional guidance. This is an opportunity to improve your skills or to determine where your professional skills lie. ChatGPT still struggles with timely analysis, directional guidance, practical recommendations beyond surface-level perspectives, and combining mathematical and textual analysis (i.e. doing word problems or math-related case studies or code review) so there is still an immense amount of opportunity for people to write better.
Ultimately, ChatGPT is a reflection of the history of written text creation, both analog and digital. Like all AI, ChatGPT provides a view of how questions were answered in the past and provides an aggregate composite based on auto-completion. For topics with a basic consensus, such as how to build a product, this tool will be an incredible time saver. For topics that may have multiple conflicting opinions, ChatGPT will try to play either both sides or all sides in a neutral manner. And for niche topics, ChatGPT will try to fake an answer at what is approximately a high school student’s understanding of the topic. Amalgam Insights recommends that all knowledge workers experiment with ChatGPT in their realm of expertise as this tool and the market of products that will be built based on the autogenerated text will play an important role in supporting the next generation of tech.
Semantic layer platform AtScale announced Thursday that it was now available on Google Cloud Marketplace. Mutual customers will be able to use AtScale on Google Cloud with services such as Google BigQuery, where they can run BI and OLAP workloads without needing to extract or move data.
Open data lakehouse Dremio announced a number of improvements this week. Among the updates: new SQL functionality, including support for the MAP data type so users can query map data from Parquet, Iceberg, and Delta Lake; security enhancements such as row and column-level policy-defined access control for users; support for INSERT, DELETE, and UPDATE on Iceberg tables, and for “time travel” to query historical data in place; as well as usability and performance improvements. Dremio also added a number of connectors, including dbt, Snowflake, MongoDB, DB2, OpenSearch, and Azure Data Explorer.
At AWS re:Invent 2022, Informatica announced three new capabilities for Informatica within AWS. Informatica Data Loader is embedded within Amazon Redshift so that mutual customers will be able to ingest data from a wide variety of systems, including AWS. The Informatica Data Marketplace now supports AWS Data Exchange, allowing customers to access and use third-party data hosted on the Data Exchange. And Informatica INFACore, INFA’s new development and data science framework, simplifies the process of developing and maintaining complex data pipelines, which can be shunted over to Amazon SageMaker Studio as a simple function, allowing users to pull prepared data from INFACore into SageMaker Studio for further use in building, training, and deploying machine learning models on SageMaker.
Data productivity platform Matillion announced a number of integrations with technical partners. Most of these integrations are accelerators that speed up some aspect of data processing between Matillion and its partners. FHIR Data, built by Matillion and Hakkoda, is a Snowflake healthcare data integrator that simplifies the process of loading FHIR data in Snowflake, then transforming it into a structured format for analytics processing. AWS Redshift Serverless Scale will let mutual Matillion-AWS customers run analytics without needing to manually provision or manage data warehouse clusters. Matillion One Click within AllCloud automates the setup and maintenance of data pipelines. Finally, the Matillion-Collibra integration creates data lineage, mapping inbound and outbound data flows, and attaches data objects to assets in the Collibra data catalog.
Analytics engine Starburst launched new capabilities for Starburst Galaxy, the managed service version of its primary Starburst Enterprise offering. The new Data Products capabilities include a catalog explorer for users to search through their data more easily and understand what they have; schema discovery, which can help users find new datasets regardless of their storage format; and enhanced security and access controls.
Starburst also announced support for AWS Lake Formation via Starburst Enterprise, which will allow joint customers to more easily implement a data mesh framework across all of an organization’s data sources.
Editorial note: While Twitter and Meta aren’t precisely on the BI to AI spectrum per se, given the sheer prevalence and use of these massive data sources and the fast-moving news around layoffs and security issues for these properties lately, Amalgam Insights would recommend confirming that you are performing backups of relevant data on a regular schedule; that you are taking available security precautions including the use of two-factor authentication where possible; and that your communications strategies are nimble enough to respond to issues of impersonation.
Spreadsheet data automation company Coefficient has raised an $18M A round. Battery Ventures led the funding round, with participation from existing investors Foundation Capital and S28 Capital. Coefficient will use the money to scale up global operations and expand its offerings.
Strategic investment firm Databricks Ventures has taken an equity stake for an undisclosed sum in Databricks partner Matillion, a data integration solution. In doing so, Databricks extends their existing partnership with Matillion, providing financial support for Matillion’s Data Productivity cloud and how it works with Databricks’ Lakehouse Platform.
Decision intelligence platform Tellius announced version 4.0 on Wednesday. Key new features include Multi-Business View Vizpads, allowing users to view and analyze across multiple data sources without needing to constantly switch between individual dashboards for each; an enhanced onboarding and ongoing user experience with walkthroughs and in-app chat; and more robust search functionality.
Graph data platform Neo4J made Neo4J 5, the next version of its cloud-ready graph database, generally available earlier this week. Among the notable improvements: new syntax making complex queries easier to write; query performance improvements by up to 1000x; automatic scaleout to handle sudden massive bursts of query activity; and the debut of Neo4J Ops Manager to monitor and manage continuous updates across global deployments.
Anaconda made two partnership announcements this week. First, Anaconda is collaborating with Domino Data Lab to incorporate the Anaconda repository into Domino’s Enterprise MLOps Platform. Domino users will be able to access Anaconda’s Python and R packages without requiring a separate Anaconda enterprise license.
Second, Snowpark for Python, the Anaconda repository and package manager within Snowflake Data Cloud, has entered public preview. Snowflake users will be able to use Python to build data science workflows and data pipelines within Snowpark.
On a related note, dbt Labs also announced support for data transformation in Python to dbt, allowing dbt customers to take advantage of Python capabilities on major cloud data platforms such as Snowflake. Joint dbt and Snowflake customers will be able to use Python capabilities for both analytics and data science projects on Snowpark.
Data management and analytics consulting firm Sagence has been acquired by PwC, adding to PwC’s existing data strategy and digital transformation capabilities. Sagence provides additional expertise and experience in creating action plans for proposed data strategies.
Enterprise data intelligence platform Alation announced a $123M Series E round of funding this week. Thoma Bravo, Sanabil Investments, and Costanoa Ventures led the round, with additional participation from new investor Databricks Ventures and existing investors Dell Technologies Capital, Hewlett Packard Enterprise, Icon Ventures, Queensland Investment Corporation, Riverwood Capital, Salesforce Ventures, Sapphire Ventures, and Union Grove. Alation will use the capital to continue accelerating product innovation and global expansion.
On November 2, Cloudera debuted the Cloudera Partner Network, redesigning their existing partner program’s approach. CPN members will see improved tools for supporting go-to-market initiatives, a FastTrack Onboarding Program to shorten time-to-market capabilities, programs for rebates and market development funds to demonstrate financial commitment, a Partner Success Team to improve training, and additional benefits to support the new CDP One SaaS solution.
At Data Citizens ’22, Collibra announced new capabilities for Collibra Data Intelligence Cloud. A new data marketplace will make it faster and easier to find curated and approved data, speeding up decision making and action. The Workflow Designer, now in beta, will help teams automate business processes in creating new workflows, and usage analytics will show which assets are most widely and frequently used. On the compliance side, Collibra also released Collibra Protect, available through their Snowflake partnership, to provide greater insight into how protected and sensitive data is being used, as well as protect said data and maintain compliance. Collibra Data Quality and Observability, when deployed in an organization’s cloud, will help organizations scale and secure their data quality operations.
On November 3, IBM launched IBM Business Analytics Enterprise, a new suite that includes business intelligence planning, budgeting, reporting, forecasting, and dashboarding capabilities. Among the key new features is the IBM Analytics Content Hub, which will let users assemble planning and analytics dashboards from a number of vendor sources. In addition, the Hub tracks and analyzing usage patterns to recommend role-based content to users.
Informatica released the State and Local Government version of their Intelligent Data Management Cloud this week. This continued expansion of vertical-specific IDMCs demonstrates Informatica’s commitment to serving a variety of government clients beyond just the federal.
Qlik released Qlik Cloud Data Integration, a set of SaaS services that form a data fabric. Among the major cloud platforms QCDI will integrate with are AWS, Databricks, Google Cloud, Microsoft Azure Synapse, and Snowflake. Data from these sources will be sent through QCDI, where it can be transformed from its raw state to analytics-ready, allowing for automated workflows for apps and APIs while accounting for metadata management and lineage.
Edge AI startup Axelera AI closed a $27M Series A funding round this week. Innovation Industries led the round, with participation from imec.xpand and SFPI-FPIM. Axelera AI will use the funding for launching and producing its AI acceleration platform, as well as hiring.
AI platform LatticeFlow secured $12M in Series A funding. Atlantic Bridge and OpenOcean led the funding round, with participation from new investors FPV Ventures and existing investors btov Partners and Global Founders Capital. The funding will go towards expanding LatticeFlow’s capacity to diagnose and repair errors in AI data and models,
AWS announced Amazon Neptune Serverless, a serverless version of their graph database service which automatically provisions and scales resources for unpredictable graph database workloads. Amazon Neptune Serverless is available today to AWS customers running Neptune in specific regions; availability in other regions is coming soon.
Bloomberg announced that it had enlarged its carbon emissions dataset to cover 100,000 companies. The dataset includes company-reported carbon data, as well as Bloomberg-generated estimates of carbon data for companies that do not have or provide carbon emissions data, and accompanying data reliability scores.
Adding to their collection of vertical-specific releases of its Intelligent Data Management Cloud, Informatica launched their Intelligent Data Management Cloud for higher education this week. IDMC helps integrate educational data from a wide variety of decentralized sources while ensuring data remains secure and compliance and privacy standards are respected.
IBM released three new libraries this week, expanding their embeddable AI portfolio. These libraries include IBM Watson Natural Language Processing Library, IBM Watson Text to Speech Library, and IBM Watson Text to Speech Library. IBM Ecosystem partners will be able to use these libraries to develop and scale AI apps more quickly.
Analytics company ThoughtSpot debuted ThoughtSpot for Sheets, a web plugin for Google Sheets. Users will be able to install and run ThoughtSpot for Sheets directly in their web browser, capable of analyzing the data available in their Google Sheets spreadsheets while minimizing the technical knowledge necessary to do so. ThoughtSpot will be compatible with additional partners in the near future.
Enterprise data catalog company data.world made several hiring announcements this week. New Chief Marketing Officer Stephanie McReynolds joined data.world from Ambient.ai, where she served as head of marketing. Prior to that, McReynolds was the SVP of Marketing and first marketing executive at fellow data catalog company Alation. New SVP of Sales Richard Yonkers came to data.world from Knoema, an enterprise data hub provider, where he served as the senior vice president of sales. Mineo Sakan was the VP of Global Finance at data protection firm HYCU prior to joining data.world as their new VP of Finance.